Before You Build: A Realistic Framework for Evaluating AI Use Cases
Why 80% of AI projects fail and how to avoid being one of them. A practitioner's framework for evaluating AI use cases before you write a single line of code.
Imagine this scenario: At 2 AM on a Tuesday, a team gets a call. Their AI-powered fraud detection system has flagged 40% of legitimate transactions as fraudulent. Customers are furious. The system has been in production for three months, and they’ve just discovered a fundamental flaw: they’d never properly validated whether AI was the right solution.
That night cost them €50K in lost revenue and three months of development time. The lesson? Most AI projects fail not because the technology is wrong, but because the use case evaluation is wrong.
McKinsey’s 2025 State of AI report (detailed analysis) finds that while 88% of organizations use AI in at least one business function, nearly two-thirds remain in experiment or pilot mode, with only about one-third having genuinely scaled AI across functions. Why? They skip the assessment phase. They jump to building before asking “Should we build this?”
This is the framework I wish we’d used back then. I apply it to every AI initiative now, before writing a single line of code.
This isn’t about “How do we build an AI/ML model?” It’s about “Does this problem actually NEED AI? And if yes, what LEVEL of AI?”
The Three Failures That Kill AI Projects
Why do AI projects fail? After working on dozens of initiatives, I’ve noticed three patterns that keep showing up:
-
Bad Problem Statement - “We want to use AI for customer support” isn’t a problem-it’s a solution looking for a problem. What’s the actual pain? Long response times? High ticket volume? Start with the business problem, not the technology.
-
Wrong Abstraction Level - Building a Level 4 (Advanced ML) system when Level 1 (Rules) would work. Over-engineering kills projects. A simple rule-based system catches 85% of cases, but teams jump to deep learning “because AI is cool.” Match the AI level to the problem complexity.
-
Wrong Expectations - Expecting 100% accuracy from day one. AI systems are probabilistic. They improve over time. Teams abandon projects when initial accuracy is 75% instead of 95%. Set realistic success criteria based on baseline performance.
A fraud detection system started at 85% accuracy with simple Logistic Regression. After two years of iteration, it reached 99.2% with ensemble models. But they almost killed it in month three because “85% wasn’t good enough.” The lesson: start simple, improve iteratively.
The 3-Dimensional Assessment Framework
Every AI use case must pass three dimensions: Desirability, Feasibility, and Viability. Fail any dimension, and the project should stop or pivot.
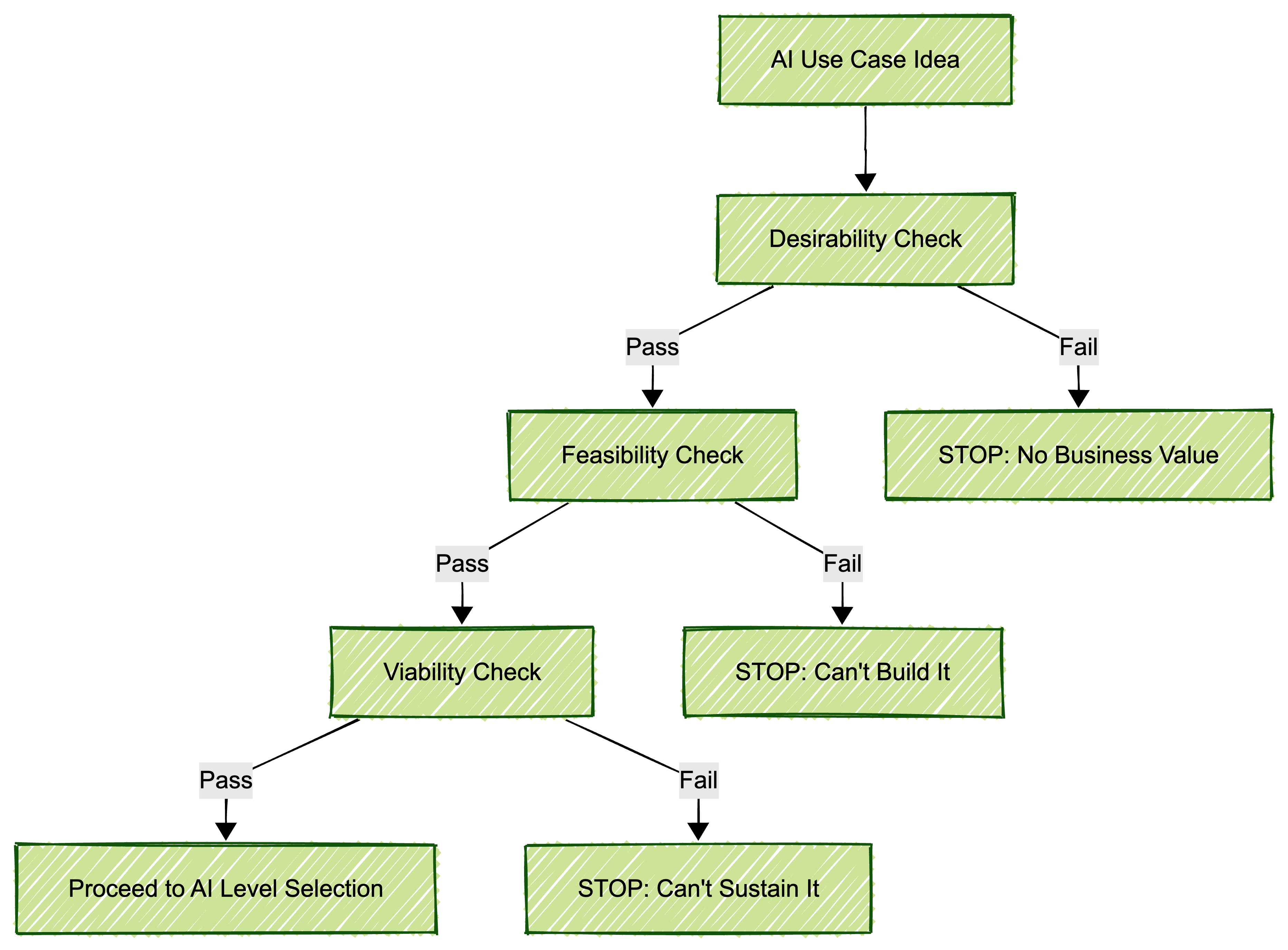
Dimension 1: Desirability - Is the Problem Worth Solving?
Question: Would solving this problem create measurable business value?
What to Assess:
-
Quantified Impact
- What’s the current cost of the problem? (Time, money, errors)
- What’s the cost of doing nothing?
- What’s the measurable improvement we need?
-
Strategic Alignment
- Does this align with business priorities?
- Is there executive sponsorship?
- Will users actually adopt this?
-
Success Metrics
- How will we measure success?
- What’s the baseline performance today?
- What improvement justifies the investment?
Example: Fraud Detection
Problem: Fraudulent transactions slip through our rule-based system
Current State: 2.8% fraud rate, costs €5M annually
Target State: Reduce to <0.8% fraud rate (€3M savings)
Baseline: Manual rules catch 1.8% fraud
Success Metric: Fraud catch rate >99%, false positives <0.5%
Red Flags:
- ❌ Vague problem statement (“improve customer experience”)
- ❌ No baseline metrics
- ❌ No clear business owner
- ❌ Success criteria are subjective
Green Lights:
- ✅ Quantified current cost
- ✅ Clear target improvement
- ✅ Measurable success metrics
- ✅ Business owner identified
Dimension 2: Feasibility - Can We Technically Do This?
Question: Do we have the data, skills, and infrastructure to build this?
What to Assess:
-
Data Reality Check
- Do we have the data we need? (Not “can we collect it”-do we HAVE it?)
- Is the data labeled? Complete? Fresh?
- How much historical data exists?
- What’s the data quality?
-
Technical Fit
- Does this problem require AI, or would rules/heuristics work?
- Do we have the technical skills in-house?
- Can we integrate with existing systems?
- Are there compliance/regulatory constraints?
-
Data Access & Governance
- Can we legally use this data?
- Do we have privacy/compliance approval?
- Who owns the data, and will they give us access?
Example: Customer Churn Prediction
Data Needed: 6-12 months of customer behavior + churn labels
Data We Have: ✅ Yes, 6-12 months per customer
Labels: ✅ Yes, but...
Issue: Some regions have only 3 months of history
Issue: Definition of "churn" varies by product
Decision: DATA EXISTS, but quality needs validation (PoC risk)
Example: Merchant Category Code Automation
Data Needed: Merchant records with correct category codes
Data We Have: ✅ Yes, 200K merchant records
Issue: Historical data is 80% correct (20% wrong categories)
Issue: No machine-readable explanations of why merchants get certain codes
Decision: Can't train ML on 80% correct labels. STOP or pivot to rules + GenAI
Red Flags:
- ❌ Data doesn’t exist (only “we could collect it”)
- ❌ Data quality <70% (too many missing values, errors)
- ❌ No labeled training data
- ❌ Compliance blockers (GDPR, industry regulations)
- ❌ Data locked in vendor systems we don’t control
Green Lights:
- ✅ Data exists and is accessible
- ✅ Data quality >85%
- ✅ Labeled training data available
- ✅ Compliance approval obtained
- ✅ Technical team has required skills
Dimension 3: Viability - Can We Sustain This?
Question: Is this financially justified and operationally sustainable?
What to Assess:
-
ROI Calculation
- Annual benefit: What will be saved/earned?
- Implementation cost: What will it cost to build?
- Operating cost: Ongoing maintenance/infrastructure
- Payback period: When does it break even?
-
Team & Skills
- Do we have the right team?
- Can we maintain this long-term?
- What training is needed?
-
Change Management
- Will users adopt this?
- What process changes are required?
- Is the organization ready?
Example: Fraud Detection ROI
Year 1 (Implementation):
├─ Implementation cost: €600K
├─ Infrastructure cost: €200K
├─ Team cost (2 FTE): €250K
└─ Total Year 1 cost: €1,050K
Annual Benefit (Ongoing):
├─ Fraud reduction: €2M/year (0.8% rate instead of 2.8%)
├─ Manual review savings: €300K/year
└─ Total annual benefit: €2.3M/year
Payback Period: Year 1 = -€1,050K + €2.3M = +€1.25M
→ Positive in Year 1. ✅ GO
Risk Scenario (50% as good):
├─ Fraud reduction: €1M/year
├─ Manual review savings: €150K/year
├─ Total benefit: €1.15M/year
├─ Payback: 0.9 years
→ Still positive. ✅ GO
Red Flags:
- ❌ Payback period >2 years
- ❌ ROI is negative even in best case
- ❌ No budget for ongoing operations
- ❌ Team doesn’t have skills (and can’t acquire them)
- ❌ Users are resistant to change
Green Lights:
- ✅ Positive ROI in Year 1
- ✅ Payback period <18 months
- ✅ Budget approved for build and operations
- ✅ Team has or can acquire skills
- ✅ Users are engaged and supportive
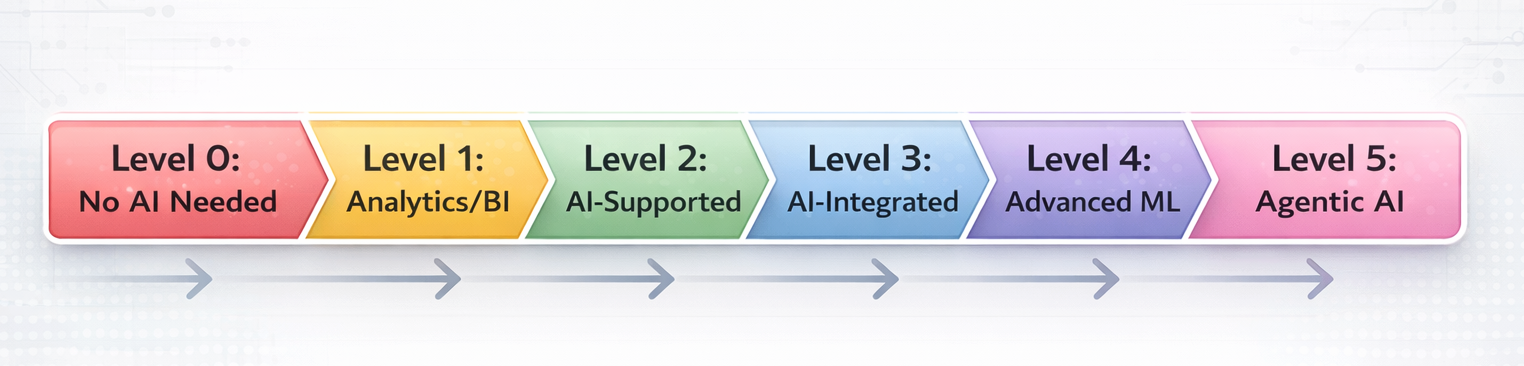
The 5 Levels of AI: From Analytics to Agentic AI
Not all AI is created equal. Understanding AI levels helps you pick the right solution for your problem and avoid over-engineering.
| Level | What It Is | When to Use | Cost | Time | Example |
|---|---|---|---|---|---|
| 0 | Rule-based logic, heuristics | Deterministic problems, rules capture all cases | €5K-20K | 2 weeks | ”If amount > €5K, flag for review” |
| 1 | Statistical models, regression | Linear relationships, historical patterns | €20K-50K | 3 weeks | Sales forecasting, customer segmentation |
| 2 | AI suggests, human decides | Human judgment critical, low error tolerance | €50K-150K | 4-6 weeks | Churn prediction: AI flags at-risk customers, team decides offers |
| 3 | AI makes decisions, automated | Routine decisions, acceptable errors, high volume | €150K-400K | 8-12 weeks | Merchant code automation: 98% automated, GenAI + rules |
| 4 | Deep learning, ensemble models | Complex evolving patterns, real-time required | €400K-1M+ | 12-24 weeks | Fraud detection: 100M+ daily transactions, 99.2% catch rate |
| 5 | Autonomous agents, multi-agent systems | Planning + execution, adaptive systems | €1M+ | 6-24 months | Multi-agent workflows (requires HITL, audit logging, kill switch) |
Start at Level 2 or 3. Most problems don’t need Level 4 or 5. You can always upgrade later if needed. Over-engineering is a leading cause of AI project failure-McKinsey’s research (analysis) shows that most organizations remain stuck in pilot mode, often because they’ve over-engineered solutions instead of starting simple.
For detailed guidance on selecting the right level, download the AI Level Decision Matrix.
The Decision Tree: Quick Reference
The framework above covers the detailed assessment. If you need a quick reference, here’s the decision flow:
Decision Matrix:
| Problem? | Simpler Works? | Data Available? | ROI Positive? | DECISION |
|---|---|---|---|---|
| YES | NO | YES | YES | ✅ GO - Build to AI level specified |
| YES | NO | UNCLEAR | YES | 🟡 POC - Run 2-4 week PoC to validate data |
| YES | NO | NO | YES | 🛑 STOP - Collect data first (or use Level 0-1) |
| YES | YES | - | - | ✅ GO - Use simpler solution, stop |
| NO | - | - | - | 🛑 STOP - No real problem |
| YES | NO | YES | NO | 🛑 STOP - Not financially justified |
For detailed step-by-step evaluation, use the AI Use Case Assessment Worksheet.
Examples: Two Use Cases
Here’s how this framework played out in two real projects:
Example 1: Real-Time Fraud Detection
- Problem: Payment processing network handles 100M+ daily transactions. Rule-based fraud detection had high false positive rates - legitimate transactions were being declined.
- Assessment:
- ✅ Desirability (€5M annual cost → €3M savings target)
- ✅ Feasibility (15+ years of labeled data, ML expertise)
- ✅ Viability (€2M+/year savings, positive Year 1 ROI)
- AI Level: Level 4 (Advanced ML) – Real-time ensemble model, sub-100ms latency
- Result: 99.2% fraud catch rate, 40% reduction in false positives, €2M+/year savings
- Key Lesson: This took two years to mature. They started with Logistic Regression at 85% accuracy, then evolved to ensemble models. Don’t expect Level 4 perfection on day one - it doesn’t work that way.
Example 2: Customer Churn Prediction
- Problem: Banking platform needs to identify at-risk customers before they switch banks.
- Assessment:
- ✅ Desirability: Early identification → retention offers
- 🟡 Feasibility: Data quality gaps between banks, varying definitions
- 🟡 Viability: €50K PoC, €200K+ full build, Year 1.5 payback
- AI Level: Level 2-3 (Predictive Analytics)
- Baseline: 72% accuracy
- Target: 82-85% accuracy
- Status:
- PoC Week 3 of 4
- Initial validation: 81% accuracy (beats 72% baseline)
- Data quality issues discovered
- Decision gate: GO, PIVOT, or STOP
- Key Lesson:
- This is what a real PoC looks like: Four weeks, clear success criteria, and decision gates.
- Spending €50K to answer a €5M question is smart.
- Data quality issues are real - it’s much better to discover them in a PoC than after six months of development.
PoC Validation: When Uncertainty Exists
If you’re uncertain about any dimension, run a 2-4 week PoC. Define success criteria BEFORE starting:
- Model accuracy ≥75% (or beats baseline by X points)
- Data quality acceptable for production
- Team can operationalize this
- ROI math holds (actual results match projections)
- Technical feasibility confirmed
Decision Points:
- All criteria met? → ✅ GO to full build
- Missed 1-2 criteria? → 🔄 PIVOT (change approach, simplify)
- Missed 3+ criteria? → 🛑 STOP (not viable right now)
Structure: Week 1 (data assessment) → Week 2 (baseline) → Week 3 (ML model) → Week 4 (decision gate)
Cost: €50K-100K for a 4-week PoC. Value: It answers “Is this solvable?” before you commit €200K-1M+ to a full build.
For the complete PoC framework, download the PoC Validation Checklist.
Common Mistakes (And How to Avoid Them)
-
“The Data is Terrible” - Data quality is 60% but building Level 4 hoping ML can fix it. Fix: STOP and clean data first, or PIVOT to rules + manual, or GO WITH CAUTION with Level 1-2 models tolerant of bad data.
-
”Simpler Works, Just Not Perfectly” - Rules solve 85% of the problem. Fix: Maybe 85% is good enough? Or run a PoC to see if AI gets to 92% and if it’s worth 3x the cost.
-
”ROI is Marginal” - Benefit is €100K/year, cost is €200K + €50K/year. Fix: STOP (payback >2 years), or POC to test cheaper approach, or PIVOT to reduce costs.
-
”We’re Uncertain” - Think it could work but not sure. Fix: Run a 2-4 week PoC. Don’t STOP because uncertain, don’t GO blindly. Use PoC to reduce uncertainty.
The AI Architecture Gate
For enterprise organizations, implement an AI Architecture Gate-a mandatory review before any AI project gets budget approval. Five gates: Problem Validation → AI Necessity → AI Level Approval → Data & Compliance → Risk Assessment.
The goal? Only justified, feasible, and safe AI use cases get budget approval. Download the AI Architecture Gate template for the complete framework.
Practical Tools & Templates
You can find all templates on the Templates page with descriptions and download options.
1. 3-Dimensional Assessment Worksheet
Download: AI Use Case Assessment Worksheet
Sections:
- Desirability scoring (1-10 for each criterion)
- Feasibility checklist (data, skills, compliance)
- Viability calculation (ROI, payback, risk)
- Overall recommendation (GO / POC / STOP)
2. ROI Calculator Template
Download: AI ROI Calculator
Includes:
- Implementation cost breakdown
- Annual benefit calculation
- Operating cost estimation
- Payback period analysis
- Risk-adjusted scenarios
3. PoC Validation Checklist
Download: PoC Validation Checklist
Includes:
- Success criteria definition
- Week-by-week PoC structure
- Decision gate framework
- Go/Pivot/Stop criteria
4. AI Level Decision Matrix
Download: AI Level Decision Matrix
Helps you:
- Understand each AI level (0-5)
- Match level to problem complexity
- Estimate cost and timeline
- Avoid over-engineering
5. AI Architecture Gate (Enterprise)
Download: AI Architecture Gate
For enterprise organizations:
- 5-gate approval process
- Problem Validation → AI Necessity → Level Approval → Data/Compliance → Risk Assessment
- Sign-offs and governance
- Mandatory before budget approval
Checklist: Are You Ready to Build?
Before moving forward, make sure you can answer all of these:
- Problem is REAL (quantified impact, clear owner)
- Simpler solutions INSUFFICIENT (tested 3-5 alternatives)
- Data EXISTS and is CLEAN (quality >85%, labeled, accessible)
- AI Level is CLEAR (start simple, can upgrade later)
- ROI is POSITIVE (payback <18 months, risk-adjusted)
- Stakeholders AGREED (business owner, technical lead, finance)
- Budget is APPROVED (build + operations)
- Team is ASSIGNED (has or can acquire skills)
If any box is unchecked: Don’t proceed. Fix it first.
Key Takeaways
-
Start with the problem, not the solution - “We want AI” isn’t a problem statement.
-
Test simpler first - Rules and heuristics solve most problems. Don’t jump straight to AI. Research shows (detailed analysis) that organizations starting with simpler solutions scale more successfully.
-
Check data early - It’s the biggest blocker. “Can we collect it?” is different from “Do we have it?”
-
Calculate real ROI - Not theoretical savings. Include implementation, operations, and risk.
-
Match AI level to problem - Start simple (Level 2-3). Upgrade later if needed.
-
Use PoCs for uncertainty - €50K to answer a €5M question is smart.
-
Embrace NO decisions - They’re success, not failure. You’ve saved months and money.
-
The goal isn’t to build - The goal is to answer: “Does this problem actually need AI?”
What’s Next
You’ve evaluated your use case. What happens now depends on your decision:
- If GO: Grab the AI Use Case Assessment Worksheet and start planning implementation
- If POC: Use the PoC Validation Checklist to structure your 4-week validation
- If STOP: Document why in the assessment worksheet. Revisit in six months-conditions change
Need help with technical implementation?
- Building Production-Ready AI Agents - For autonomous systems
- Prompt Engineering Beyond Basics - When you’re ready to build
I offer office hours for teams evaluating AI use cases. Book a session to walk through the framework with your specific problem. Contact me to schedule.
Views expressed are my own and do not represent my employer. External links open in a new tab and are not my responsibility.
What AI use cases are you evaluating? I’d love to hear about your experiences. Connect with me on LinkedIn or reach out directly.
Discussion
Have thoughts or questions? Join the discussion on GitHub. View all discussions