Context Window vs Attention Window: What AI Architects Must Understand
Context size is not the same as attention behavior. A practical guide for LLM architecture, RAG design, and long-context system trade-offs.
Two terms keep getting mixed in AI discussions:
- context window
- attention window
They are related, but they are not the same. If you build long-document workflows, copilots, or agent systems, this distinction affects quality, latency, and cost.
Context size is a capacity number. Attention behavior is a reasoning quality and compute pattern.
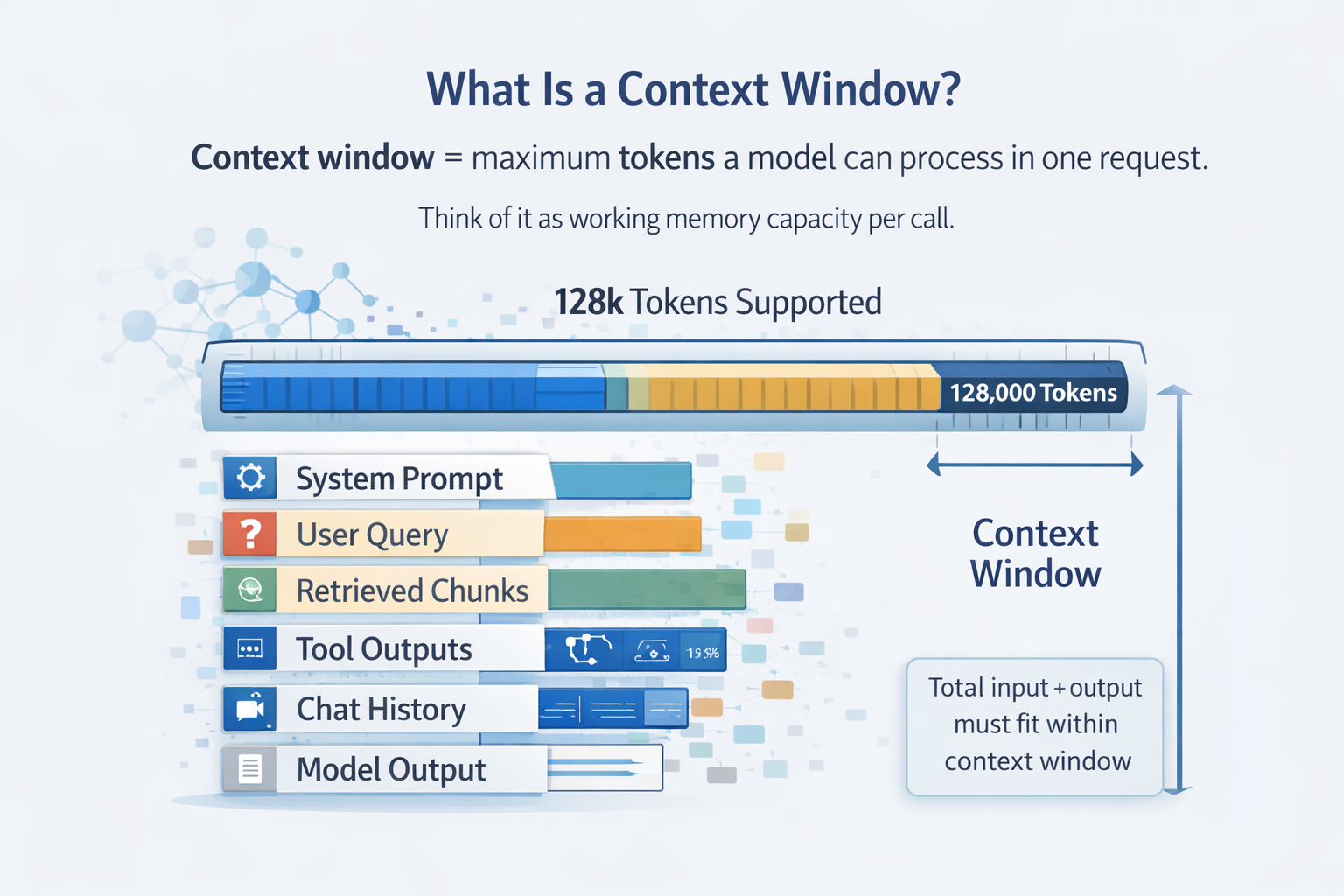
1. What Is a Context Window?
Context window is the maximum tokens the model can process in one request.
It includes:
- system prompt
- user query
- retrieved chunks
- tool outputs
- chat history
- model output
If a model supports 128k tokens, your input plus output must fit inside that 128k budget.
Think of context window as working memory capacity per call.
Example token budget
| Component | Tokens |
|---|---|
| System Prompt | 2,000 |
| User Query | 500 |
| Retrieved Docs | 90,000 |
| Chat History | 10,000 |
| Model Output | 5,000 |
| Total | 107,500 |
This request is safe on a 128k model. At 129k, you hit truncation or failure depending on the provider behavior.
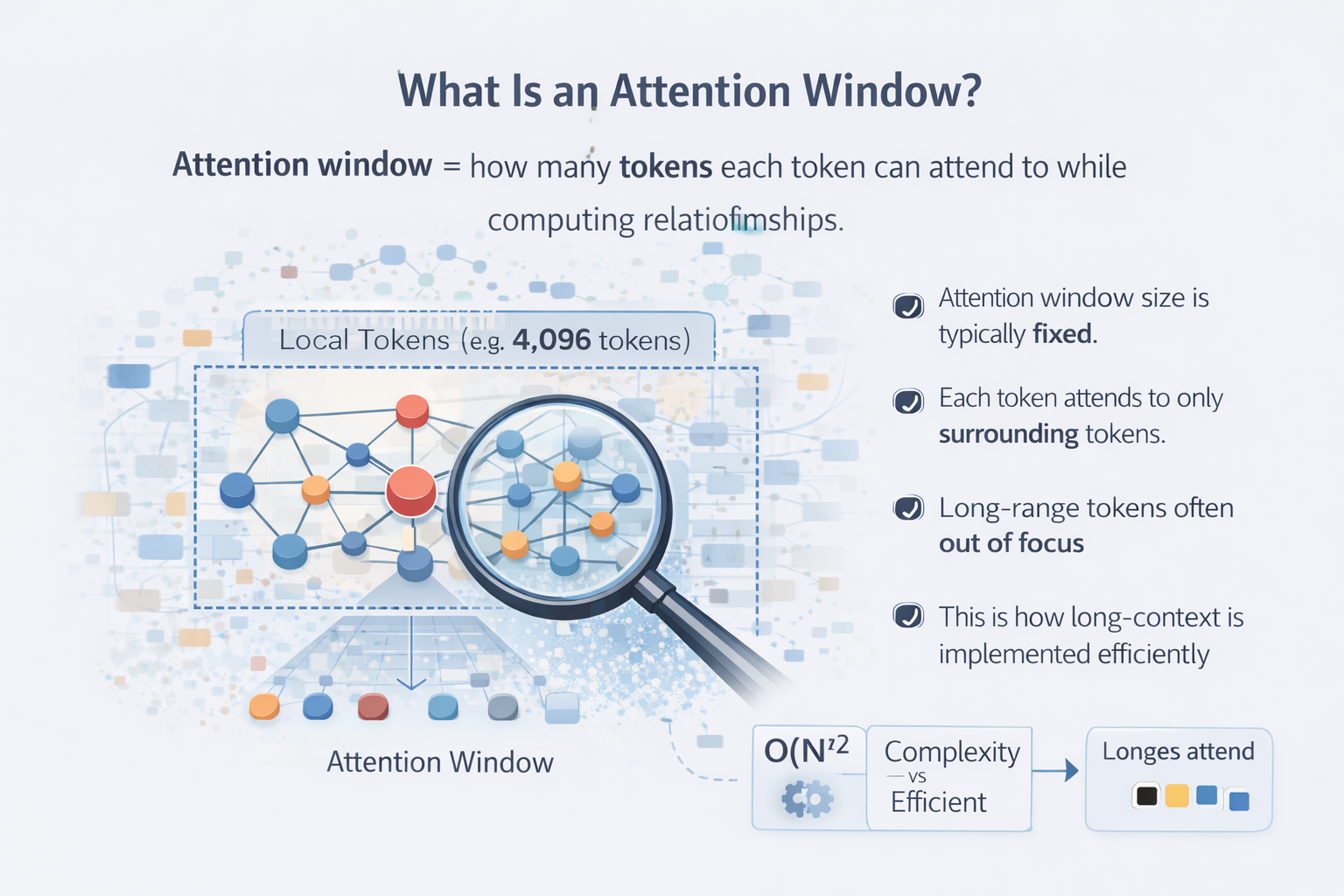
2. What Is an Attention Window?
Attention window describes how much context each token can effectively reference during computation. This is about internal attention mechanics, not only the headline context number.
In vanilla transformers, every token attends to every other token. That gives quadratic complexity:
- 10k tokens means around 100 million pair interactions
- 100k tokens means around 10 billion pair interactions
This is why long context becomes expensive quickly.
3. Why Context Window Is Not Attention Window
Many models advertise very large context limits. That does not mean dense full attention over all tokens at all times.
Long-context implementations often use techniques like:
- sliding window attention
- sparse attention
- local plus global token mixing
- memory compression
- attention sinks
So yes, the model can ingest a large prompt. No, it may not reason across the full prompt with equal fidelity.

4. How Long Context Is Actually Achieved
Common optimization patterns:
- sliding window attention
- grouped query attention
- flash attention kernels
- RoPE scaling or ALiBi style biasing
- external memory or compressed memory tokens
These unlock larger context budgets and lower compute pressure. They also introduce practical trade-offs:
- long-range degradation
- recency bias
- context dilution
- unstable reasoning near maximum utilization
5. System Design Implications
This is where most architecture errors happen.
Just because it fits does not mean it is used well
A 200k prompt in a 200k model does not guarantee equal reasoning over first and last segments. Signal quality degrades with distance and noise.
RAG should not dump everything
Even with large context limits:
- rank before inject
- chunk by semantic boundaries
- rerank top candidates
- compress low-value context
Long chat history is not long-term memory
Context is per-request and ephemeral. When it overflows, old turns get dropped.
Durable memory requires separate system layers:
- vector retrieval
- summarization memory
- state store with retrieval policies

6. Simple Analogy
- Context window is how many books you can place on your desk.
- Attention window is how many pages you can truly compare at once.
You can place many books. You still reason over a smaller active slice at a time.
7. What To Ask When Evaluating a Model
Do not stop at “what is the max context.” Ask the questions that reveal behavior.
- Is long context full attention or sparse/sliding patterns?
- How does quality change after 50 percent context utilization?
- What is the latency curve across 25 percent, 50 percent, and 90 percent load?
- How does retrieval quality affect answer accuracy at long lengths?
- What is the cost increase per extra 10k tokens in real production traffic?
8. Emerging Direction
The field is moving toward hybrid strategies:
- linear and sub-quadratic attention variants
- retrieval-augmented transformer stacks
- state-space and memory-augmented components
- external memory layers outside core attention
The likely future is not one giant dense attention pass over everything. It is selective retrieval plus targeted reasoning.
Key Takeaway for AI Architects
When evaluating a model, do not ask only:
“What is the context window?”
Also ask:
- Is it full attention?
- Is it sliding window?
- How does long-range attention decay?
- What happens past 50 percent utilization?
- What do real-world benchmarks show for your workload?
Context size is a marketing number. Attention behavior is the architectural truth.
Context size is the marketing number. Attention behavior is the architectural truth.
References
- Attention Is All You Need (Vaswani et al., 2017)
- FlashAttention
- Grouped-Query Attention (Ainslie et al., 2023)
- LongRoPE
- ALiBi
Views expressed are my own and do not represent my employer. External links open in a new tab and are not my responsibility.
Discussion
Have thoughts or questions? Join the discussion on GitHub. View all discussions