Recursive Language Models: Why Smarter Navigation Beats Bigger Memory
RLMs solve the context window problem by letting AI write code to explore information. The result? Tasks going from 0% to 91% success. Here's how it works and when to use it.
At 3 AM, your AI code reviewer gives up. It’s analyzed 200 files of your 5-million-line codebase and hit the context limit. The critical security vulnerability? Buried in file #847. Your AI never saw it. This isn’t a bug - it’s a fundamental limitation of how AI remembers information.
But what if AI didn’t need to remember? What if it could explore information like a programmer writes code?
That’s the promise of Recursive Language Models (RLMs). Instead of cramming everything into memory, RLMs treat data as an external environment and let AI write code to explore it intelligently. Early benchmarks show transformative results: tasks going from 0% to 91% success on problems that previously failed entirely1.
This isn’t about bigger context windows. It’s about smarter context navigation.
RLMs don’t make context windows bigger. They make context windows irrelevant.
The Problem: Why Context Windows Fail
Every Large Language Model has a maximum number of tokens it can process in a single request. GPT-5 handles roughly 100,000–200,000 tokens - about 75,000 to 150,000 words2. That sounds like a lot until you realize a typical codebase can span millions of lines, or a research corpus might contain thousands of documents.
The transformer architecture creates this bottleneck. Each token must mathematically “attend” to every other token in the context window. This attention mechanism scales quadratically: processing 200,000 tokens is exponentially more expensive than 100,000. Cost can multiply up to 50x as context grows2.
But there’s a subtler problem called the “lost-in-the-middle” effect3. Models trained on shorter sequences perform poorly when critical information is buried in the middle of a long input. Information near the beginning and end gets better attention than information in the center.
Real-world impact:
- Summarizing a year’s worth of emails? Critical emails in the middle get ignored.
- Analyzing a 500-page codebase? Important bug patterns in the middle get missed.
- Legal document review? Buried clauses get overlooked.
Current workarounds like Retrieval-Augmented Generation (RAG) help, but they assume you know which small parts are relevant. RAG excels at quick lookups but fails when tasks require cross-referencing, complex reasoning, or handling all information holistically3.
RAG assumes you know what to retrieve. But what if you don’t? What if the answer requires understanding relationships across thousands of documents?
The Paradigm Shift: RLMs Explained
Traditional LLMs follow a linear approach: Read all → Encode → Remember until context runs out.
RLMs flip this entirely: Decompose → Write code → Recursively explore → Synthesize answer.
Here’s how it works:
1. Load Data into a Python Environment
The entire document, codebase, or dataset is stored as a Python variable in a REPL (Read-Eval-Print Loop)1. The data lives outside the model’s context window - accessible only through code execution.
2. AI Writes Code to Navigate
The model doesn’t try to remember everything. Instead, it writes Python code to search, filter, and analyze the data4. Think regex queries, chunking strategies, or pattern matching - whatever the task requires.
3. Recursive Problem Solving
For complex tasks, the AI can call itself or other LLMs on subsets of data, combining results intelligently1,4. Each sub-LLM call operates on a focused, bounded context while the main model orchestrates the overall strategy.
4. Final Synthesis
The model assembles insights from all recursive calls into a coherent answer1. The answer emerges via an iterative variable (the answer dictionary with a content key) that the model refines across turns - not generated in a single pass4.
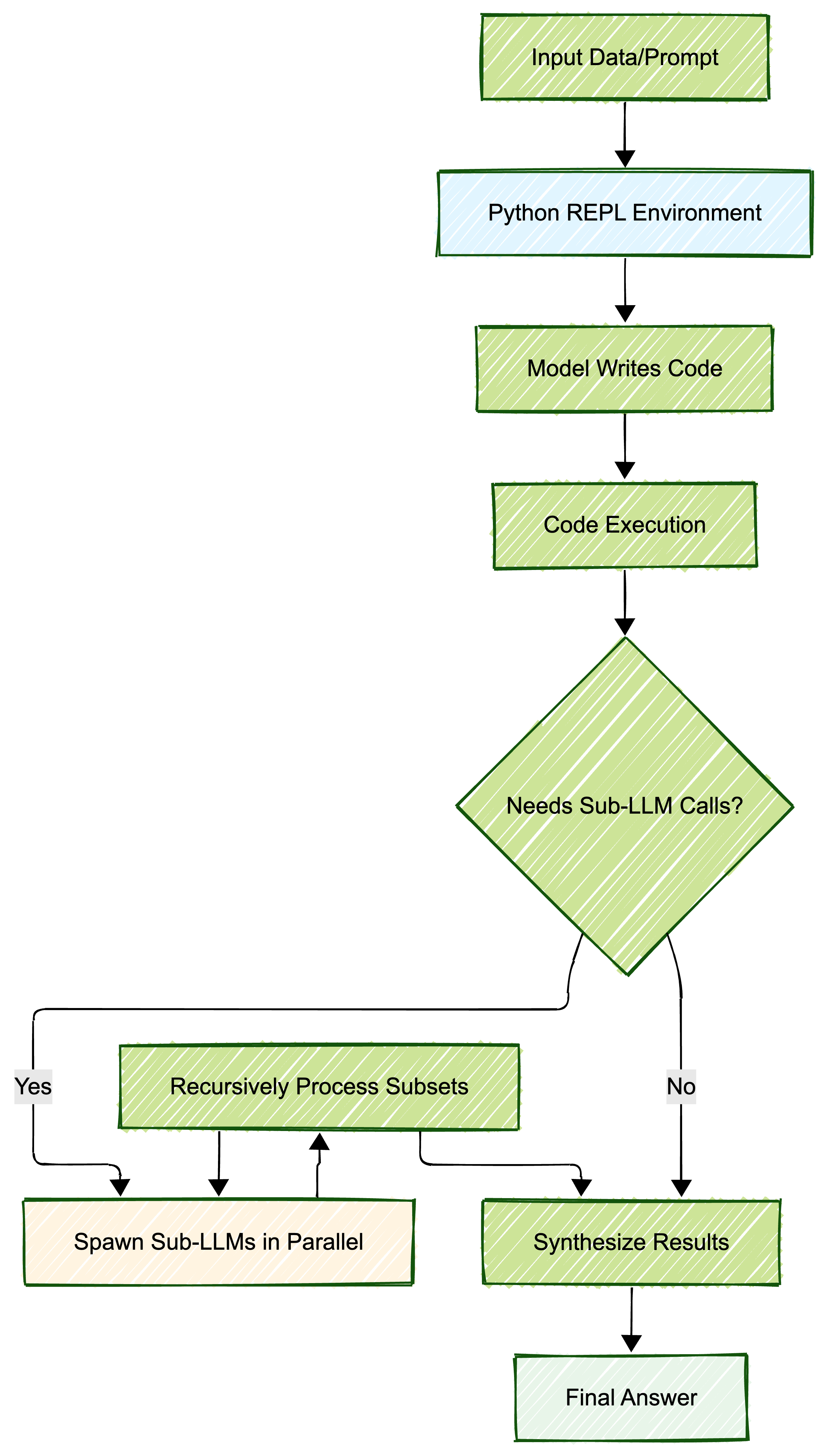
The RLM architecture includes three key capabilities1:
- Persistent Python REPL - External memory that never fills up
- Sub-LLM Delegation - Parallel processing of focused subsets
- Answer Variable Refinement - Iterative synthesis instead of single-pass generation
Raw data stays in Python variables (accessible only via print-limited output: ~8,192 characters per turn)1. The model writes code to filter, search, and transform data4. When needed, sub-LLMs process focused subsets in parallel via llm_batch() calls1. Final answers are built iteratively - not generated in a single pass4.
Think of RLMs as AI acting like a programmer: writing code to explore data, not trying to memorize it all.
The Proof: One Compelling Example
Consider this scenario: You need to summarize key insights from 100 research papers - roughly 10 million tokens of content.
Traditional LLM approach:
- Can only load ~5 papers (500K tokens) before context fills up
- Misses cross-document patterns
- Result: Incomplete, shallow summary
RLM approach:
- Loads all 100 papers into Python environment (accessed only via REPL queries)1
- Writes code: filtering via keywords or regex to identify relevant papers4
- Delegates analysis: Spawns sub-LLMs in parallel to analyze subsets, each with bounded context1
- Synthesizes: Main model combines results without ever loading full corpus directly4
- Result: Comprehensive analysis with cross-paper connections
The BrowseComp-Plus benchmark tells the story: RLM achieves 91% accuracy on 6M-11M token corpora vs. base LLM 0% (the base model couldn’t even process the input)4.
But it’s not just research papers. The CodeQA benchmark shows RLMs analyzing codebases from 23K to 4.2M tokens with 62% accuracy (GPT-5) vs. base models at 24%4. The OOLONG-Pairs benchmark demonstrates even more dramatic results: 0.04% → 58% on quadratic reasoning tasks4.
BrowseComp-Plus: 0% → 91% (GPT-5)
CodeQA: 24% → 62% (codebase analysis)
OOLONG-Pairs: 0.04% → 58% (quadratic reasoning)
These aren’t incremental improvements. RLMs enable previously impossible tasks1. When base models hit the context wall and fail entirely, RLMs succeed by changing the fundamental approach.
When to Use RLMs
Not every problem needs an RLM. Here’s a practical decision framework:
Use RLM when:
- Cross-document reasoning is required (synthesizing insights across hundreds of papers)
- Massive codebases need holistic analysis (millions of lines, architectural patterns)
- Information can’t be pre-filtered (you don’t know what’s relevant upfront)
- Complex relationships matter (dependencies, causality, patterns across data)
Use RAG when:
- Quick lookups are sufficient (fact-checking, known search patterns)
- Billion-doc corpora need initial filtering (RAG for filtering, then RLM for reasoning)
- Similarity-based retrieval works (semantic search finds relevant chunks)
Hybrid approach (future): RAG for initial filtering over massive corpora → RLM for deep reasoning on filtered subset3,4. This combines the best of both: RAG’s efficiency at scale with RLM’s capability for complex reasoning.
| Approach | Best For | Limitations |
|---|---|---|
| Traditional LLM | Short documents, single queries | Context window limits, lost-in-middle |
| RAG | Quick lookups, known patterns | Assumes you know what to retrieve |
| RLM | Cross-document reasoning, massive codebases | Higher latency, requires code execution |
If you need to understand relationships across thousands of documents or millions of lines of code, RLM is your answer. If you know exactly what to look up, RAG is faster and cheaper.
The Future and Limitations
RLMs aren’t perfect. Current limitations include:
- Sub-optimal recursion - Models not trained for RLM sometimes waste tokens by repeating work or making inefficient navigation choices4
- No explicit training yet - Current results use off-the-shelf models (GPT-5, Qwen3) not optimized for RLM scaffolding4. Purpose-built RLM models are expected to show 2-5x performance improvements via end-to-end reinforcement learning training1
- Math reasoning gap - RLMs currently underperform on mathematical problems by 15-25% vs. base models, suggesting domain-specific improvements needed1
But the future is bright. What’s coming in 2026 and beyond:
- Purpose-built RLM models - Explicitly trained for recursion via reinforcement learning1
- Hybrid RLM+RAG systems - RAG for initial filtering, RLM for deep reasoning3,4
- Asynchronous sub-LLM parallelization - Reducing latency from 40-80% overhead4
- Long-horizon agents - Breaking complex problems into subproblems, delegating to sub-agents, and synthesizing answers over weeks or months1
Prime Intellect predicts RLMs will become “the paradigm of 2026” for building long-horizon agents1. The question isn’t “Will RLMs work?” but “How quickly will the field adopt and optimize them?“1,4
RLMs aren’t perfect, but they’re proven. The benchmarks speak for themselves: tasks going from 0% to 91% success. The paradigm is here. Are you ready?
Conclusion
Recursive Language Models represent a fundamental rethinking of AI architecture. Instead of asking “How do we make models bigger to remember more?” RLMs ask “How do we make models smarter at navigating information?”
This shifts the bottleneck from hardware (GPU memory) to reasoning capability1. By decoupling memory from model size and enabling intelligent navigation, RLMs solve problems that brute-force scaling never could.
If you’re working with long-context challenges today, start experimenting: Load your documents into a Python REPL, write code to explore them, and observe how an AI model reasons through complexity differently.
The future of AI intelligence isn’t about bigger context windows - it’s about smarter navigation through unbounded information.
The paradigm of 2026 is here. Are you ready?
References
[1] Prime Intellect. (2026). Recursive Language Models: The paradigm of 2026. Retrieved from https://www.primeintellect.ai/blog/rlm
[2] Hakia. (2024). Context Windows Explained: Why Token Limits Matter. Retrieved from https://www.hakia.com/tech-insights/context-windows-explained/
[3] Michael J. Blackwell. (2026). RAG vs RLM: When to Use Each for Efficient AI. LinkedIn. Retrieved from https://www.linkedin.com/posts/michael-j-blackwell
[4] Zhang, A., Kraska, T., & Khattab, O. (2025). Recursive Language Models. arXiv:2512.24601. Retrieved from https://arxiv.org/abs/2512.24601. MIT CSAIL. Full paper: https://arxiv.org/abs/2512.24601v1
Disclaimer: The views and opinions expressed on this site are my own and do not necessarily reflect those of my employer. Content is provided for informational purposes based on my experience building AI systems. Technical implementations and approaches may vary based on specific use cases, organizational requirements, and versions of tools, packages, and software dependencies.
External Links: This blog may contain links to external websites, resources, and citations. I am not responsible for the content, privacy practices, or security of external sites. External links open in a new tab for your convenience. Please review the privacy policies and terms of service of any external sites you visit.
Discussion
Have thoughts or questions? Join the discussion on GitHub. View all discussions