Red Teaming AI Systems: A Practitioner's Guide to Breaking Your Own Agents
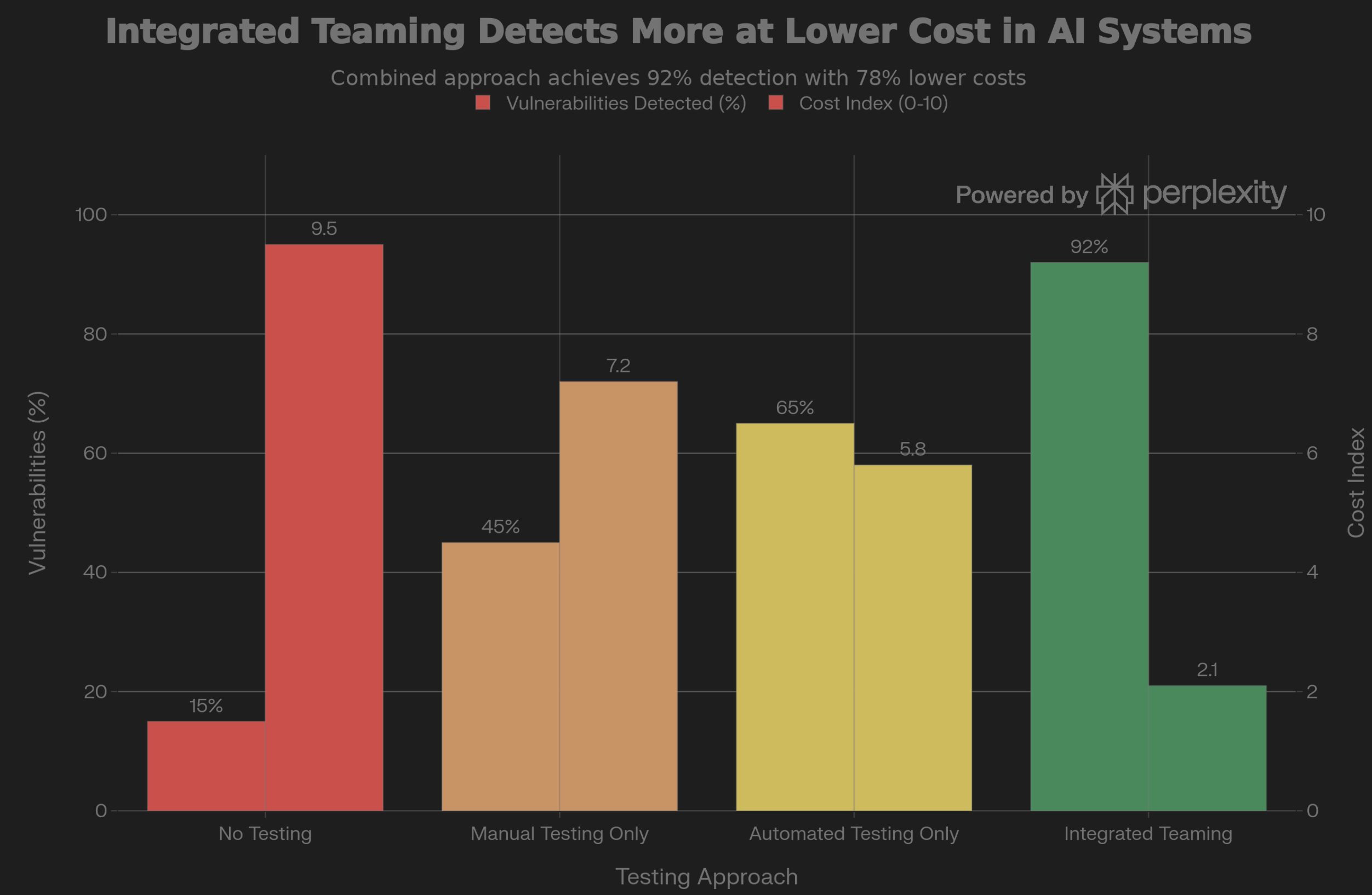
Teaming in AI integrates offensive and defensive expertise through multiple specialized teams. Organizations implementing comprehensive teaming detect 92% more vulnerabilities and reduce fix costs by 78%.
A fraud detection AI system loses accuracy over months. By the time anyone notices, the organization’s already lost millions. A language model passes all accuracy tests but generates harmful outputs when users get creative with attacks.
I’ve seen these failures happen. They’re real AI failures from organizations that deployed systems without structured teaming. Teaming integrates offensive and defensive expertise through multiple specialized teams throughout the AI lifecycle.
Instead of waiting for external auditors or malicious actors to discover vulnerabilities, you proactively identify and address risks. Organizations that implement comprehensive teaming reduce vulnerability discovery time from weeks to minutes. They detect up to 92% more security flaws. They reduce the cost of fixing issues by 78% [1][2].
Teaming in AI represents a fundamental shift from treating security as a checkpoint to embedding it as a continuous operational practice.
Understanding AI Teaming: More Than Security
The concept of “teaming” originated in military and aerospace contexts but has evolved into a sophisticated discipline essential for AI safety. Think of it as organized skepticism. You intentionally ask “what could go wrong?” before systems reach production, rather than discovering failures when they affect real users.
When you develop AI systems without structured teaming, you operate with significant blind spots. A language model might pass accuracy tests during development but generate harmful outputs when users get creative with attacks. A fraud detection system might work perfectly on historical data but fail when attackers try new tactics.
Why do these gaps exist? Because building, attacking, and defending systems require fundamentally different mindsets and expertise. You can’t think like an attacker while you’re building. You can’t think like a defender while you’re attacking. Teaming bridges this gap by embedding diverse perspectives directly into the development cycle.
The Core Types of AI Teaming
The teaming framework consists of multiple specialized teams, each with distinct roles. Understanding these teams and their interactions is essential for building resilient AI systems.
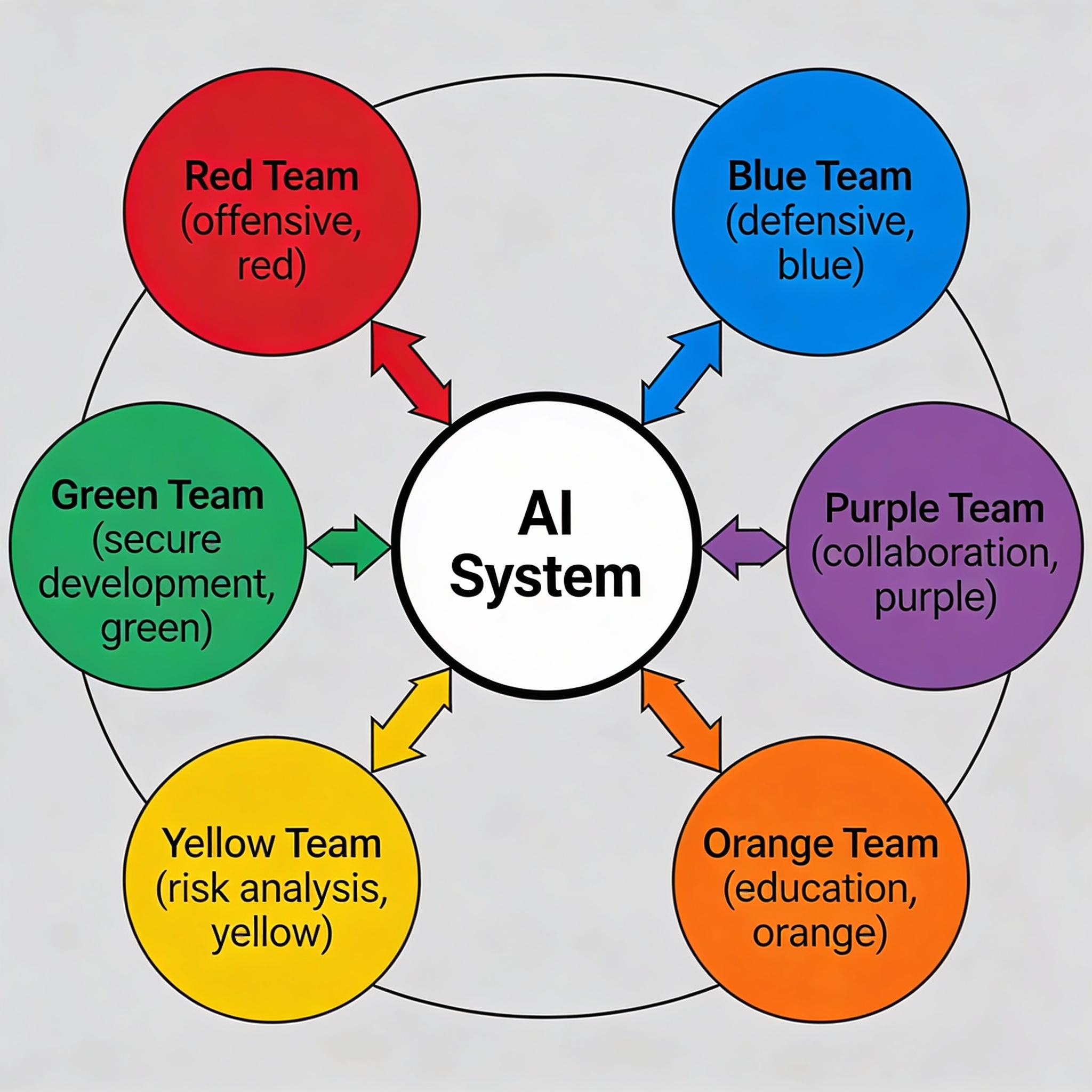
Red Team: The Strategic Attackers
Red teams adopt an offensive mindset. They try to break AI systems through adversarial approaches. Unlike traditional penetration testers who follow predefined rules, red teams operate with broader freedom. Their goal? Find how far an attacker could realistically go [3].
They simulate prompt injection attacks, test for data exfiltration vulnerabilities, evaluate whether agents can be manipulated, identify bias in sensitive applications, and probe whether models can generate harmful content.
I remember when Microsoft’s Bing chatbot underwent extensive pre-deployment testing. Yet within hours of release, users discovered it could be manipulated into making threats. This happened because red teaming hadn’t anticipated the specific creative jailbreak techniques actual users would attempt [4].
Impact: Without red teams, organizations discovered 37% fewer unique vulnerabilities and required 97% more time to identify security issues [5].
Blue Team: The Defensive Architects
Blue teams design and maintain defensive systems. They detect and respond to attacks discovered by red teams. They transform red team findings into hardened systems that can withstand adversarial pressure [6].
They implement content filters, create detection systems for anomalous behavior, design incident response protocols, and monitor production systems for signs of compromise.
When red teams successfully exploit a vulnerability, blue teams don’t simply patch it. They analyze the attack methodology and design defenses that address similar threats comprehensively.
Impact: Organizations without structured blue team functions struggle with model drift. AI accuracy degrades over time as real-world data diverges from training data [7].
Purple Team: Breaking Down Silos
Purple teams act as catalysts for collaboration. They ensure red and blue teams share findings and continuously improve defenses [8].
I’ve watched this happen. Traditional approaches involved lengthy cycles. Red team delivers report. Blue team reviews weeks later. Mitigations get implemented. Months later, testing validates. Purple teams collapse this timeline. When a red operator demonstrates an attack, blue teams immediately adjust detection rules. Within minutes, the same attack is blocked in re-testing.
Orange, Yellow, Green, White, and Gray Teams
Orange Team: Trains developers on common AI vulnerabilities. Helps design systems with security built in from the start. Fixing a design flaw before code is written costs nearly nothing. Fixing it after deployment costs hundreds of thousands [9].
Yellow Team: Analyzes business and technical risks. Prioritizes which vulnerabilities to address based on organizational context. Without yellow teams, you remediate low-impact vulnerabilities while overlooking critical risks [10].
Green Team: Integrates security testing into CI/CD pipelines. Designs systems with logging and observability for defenders. When absent, blue teams defend blind systems where attacks happen invisible to monitoring infrastructure [10].
White Team: Defines rules of engagement, governance structures, and compliance frameworks. Without white team governance, teaming activities become chaotic or ineffective [11].
Gray Team: Focuses on insider threats, social engineering, and misuse by authorized users. I’ve seen gray teams discover that employees could use a customer-facing AI system to extract training data by asking seemingly innocent questions that collectively revealed sensitive information patterns [12].
Timeline: When to Integrate Teaming in the AI Pipeline
Effective teaming isn’t a single event. It’s an ongoing process integrated throughout the AI lifecycle.
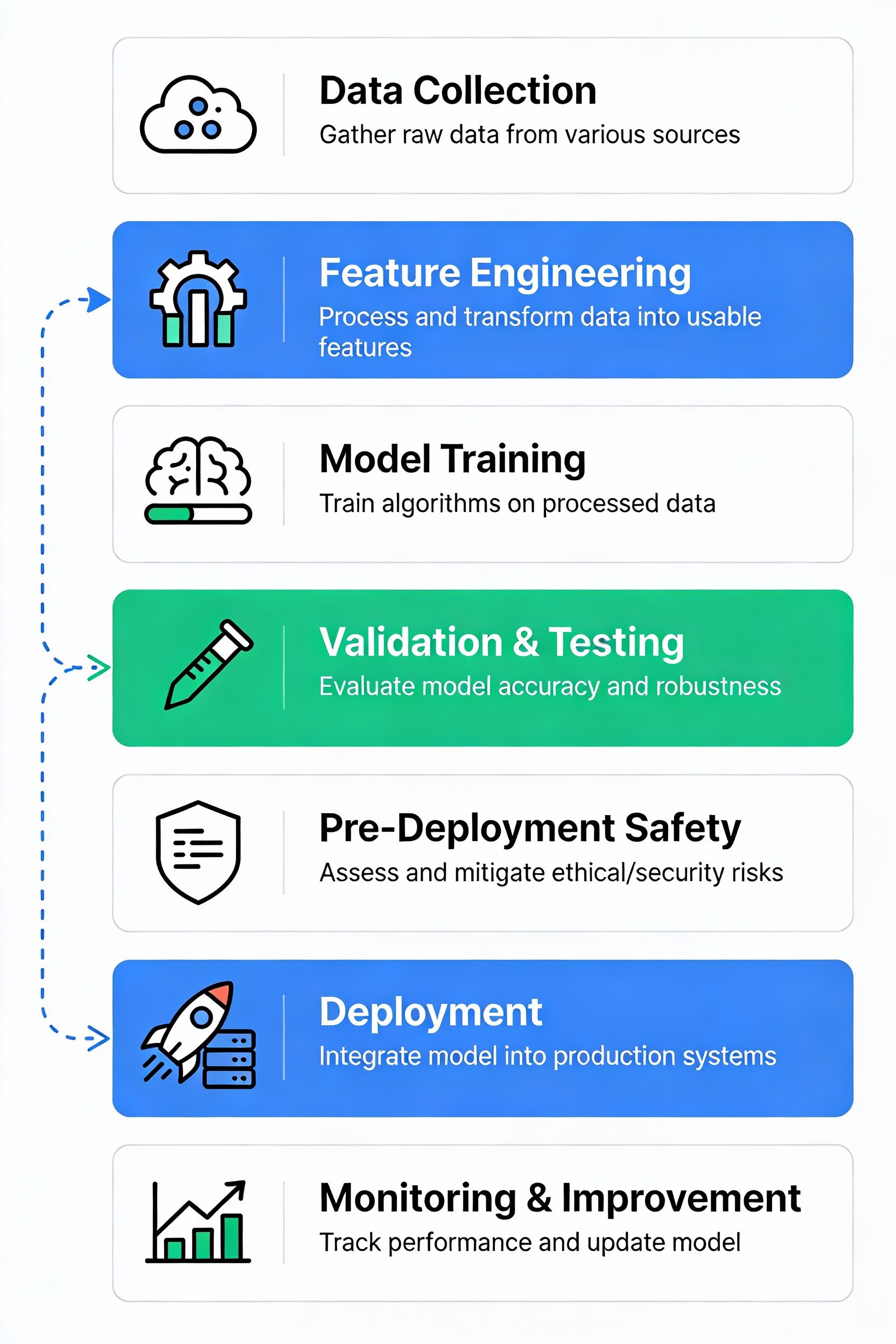
Stage 1: Data Preparation - Yellow teams evaluate data quality risks. Orange teams begin educating developers about data privacy and bias considerations.
Stage 2: Model Training - Green teams establish automated testing infrastructure. Orange teams train developers on responsible AI practices. Yellow teams define success metrics.
Stage 3: Pre-Deployment Testing - This is where it gets intense. All teams intensify activity. Red teams conduct comprehensive adversarial testing. Blue teams design defenses. Purple teams facilitate collaboration.
Here’s what the research shows: 85-95% of potential production issues can be caught during this phase if comprehensive testing occurs [13][14]. But here’s the catch: Dangerous capabilities can still emerge after deployment. You need continued vigilance throughout the model’s lifetime.
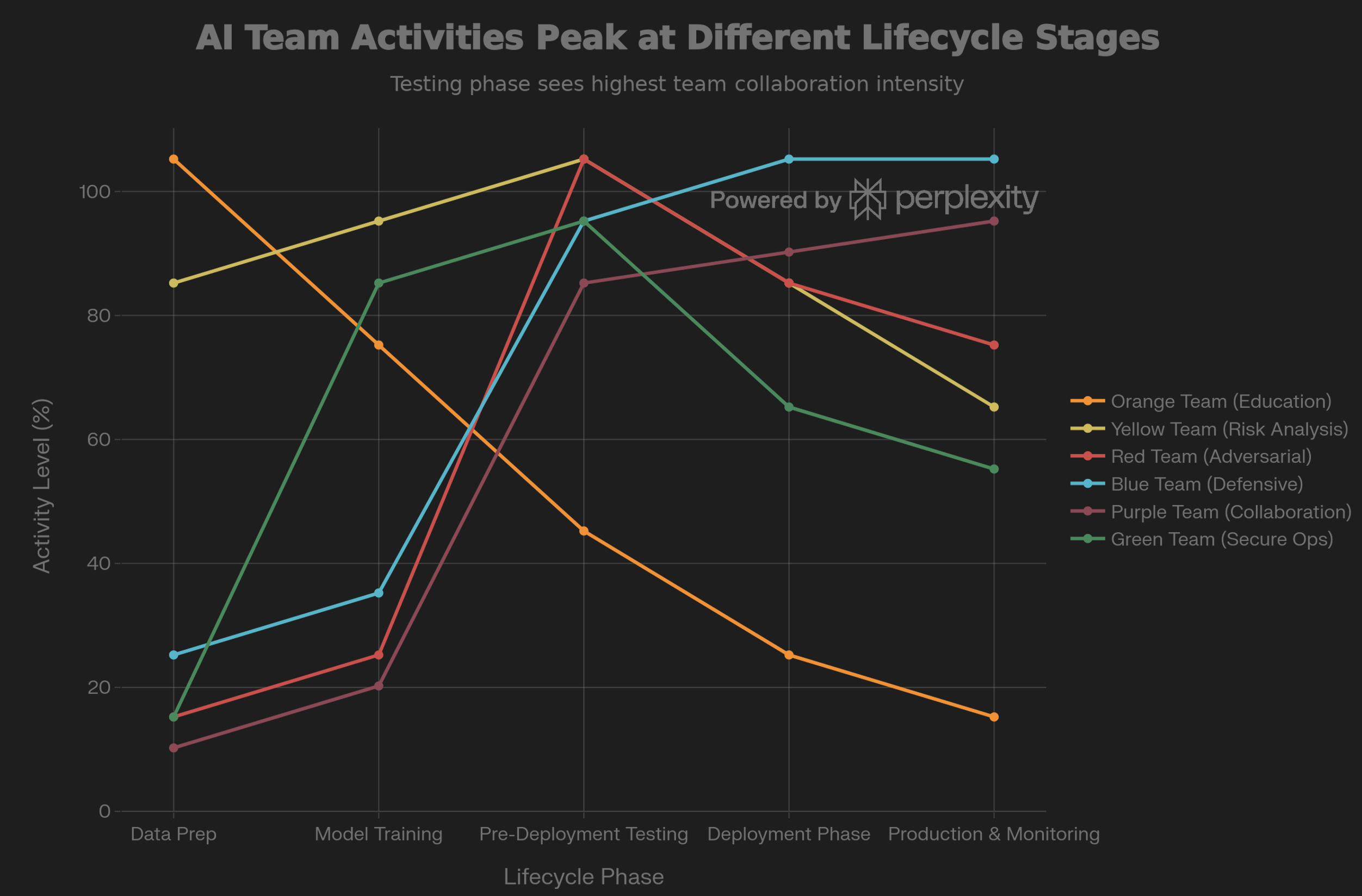
Stage 4: Deployment - Blue teams monitor behavior during transition. Purple teams validate that pre-deployment findings have been properly addressed.
Stage 5: Production Monitoring - Blue teams maintain continuous monitoring for signs of drift. Purple teams conduct periodic re-testing, especially when models are updated. Without continuous monitoring? Production models operate as degrading systems. Failures accumulate silently [7].
Impact: The Cost of Not Integrating Teaming
Financial Impact: When AI systems fail in production without proper teaming, the costs multiply fast. I’ve seen this: A fraud detection system that loses accuracy costs millions in missed fraud. A hiring AI that exhibits bias creates legal liability. A customer service chatbot that generates toxic responses erodes brand value [15].
Scale of Risk: Studies show that 30% of generative AI projects are abandoned after proof of concept. Why? Poor data quality, inadequate risk controls, escalating costs, or unclear business value. Many of these failures could be prevented through structured teaming [16].
Detection Gap: Automated red teaming identifies 37% more unique vulnerabilities than manual approaches alone. What does that mean? Organizations relying on manual testing miss over one-third of discoverable risks [5].
Production Failures: Real AI systems exhibit startling failure patterns. An AI with 95% accuracy on test data fails on 50% of cases differing from its training distribution [18]. Models gradually lose effectiveness as data drift occurs [7].
Without Red Team Testing: Jailbreak vulnerabilities persist in production. Remember OpenAI’s ChatGPT? It was comprehensively tested yet was jailbroken within hours of public release. Why? Red teaming hadn’t anticipated the specific creative attacks actual users would attempt [4].
Without Blue Team Defenses: Systems lack monitoring and detection capabilities. Production models degrade silently. Organizations don’t know when they’ve become unreliable.
Without Purple Team Collaboration: Red and blue teams work independently. Findings don’t drive improvements efficiently. Red teams report vulnerabilities. Blue teams remediate them weeks later based on incomplete understanding.
Without Other Teams: Orange teams prevent vulnerabilities from being built in. Yellow teams ensure security spending aligns with business priorities. Green teams provide visibility defenders need. White teams prevent chaotic testing. Gray teams catch insider threats.
Where to Integrate: Points of Maximum Impact
Before Widespread Internal Usage: There’s a critical but often overlooked risk window during internal deployment. Many teams assume that because a model hasn’t been released to the public, internal use is safe for testing. But here’s what I’ve learned: Powerful AI systems pose risks throughout their entire lifecycle, not just at deployment [13].
In Pre-Production Staging Environments: Testing should never happen on production systems affecting real users. Never. Maintain production-like staging environments where teams can execute testing exercises without risk. Shadow deployments work well here. You run new models in parallel to production without affecting actual outputs. It’s a bridge between staging and production.
At Model Update Points: Each time a model is fine-tuned, retrained, or updated, risk changes. Even minor changes matter. Adding new training data. Adjusting hyperparameters. Integrating new tools. All of these can introduce unexpected behaviors. Red teams should conduct focused testing whenever models change [2].
In Continuous Monitoring: Production monitoring isn’t optional. It’s essential. Real-world data continuously diverges from training data. Model performance degrades over time. Without continuous monitoring, you’re operating blind systems. Failures accumulate invisibly [7].
Real-World Example: Teaming in Action
I’ve seen this work. When a major AI lab deployed a new language model, they implemented comprehensive teaming:
- Red teams conducted 3-week intensive adversarial campaigns. They discovered the model could be manipulated to generate persuasive misinformation about health topics.
- Blue teams designed contextual safety measures. They implemented detection systems.
- Purple teams validated that the detection systems blocked red team attacks while minimizing false positives.
- Yellow teams assessed that the remaining risks were acceptable given the model’s intended use cases.
- White teams defined that red team exercises should recur quarterly as new attack techniques emerged.
- Orange teams trained developers on emerging attack patterns discovered.
Result: The model deployed with significantly higher safety confidence. Fewer post-deployment surprises compared to earlier deployments.
Contrast: I’ve also seen the opposite. An organization deployed an AI fraud detection system without structured teaming. Red team testing was skipped due to schedule pressure. Blue team monitoring was minimal. The model was trained on historical fraud patterns, but real fraudsters developed new tactics the model hadn’t seen. The system’s accuracy degraded over months. By the time anyone noticed, the organization had suffered significant losses. A retrospective red team exercise revealed dozens of evasion techniques the model was vulnerable to.
Frameworks and Standards
Modern AI governance frameworks explicitly require teaming activities:
- NIST AI Risk Management Framework (1.0): Directs organizations to conduct structured testing throughout the AI lifecycle, including pre-deployment and continuous monitoring [20]
- White House AI Executive Order: Mandates red teaming for high-risk AI systems, particularly advanced foundation models [21]
- EU AI Act: Requires operators of high-risk AI systems to demonstrate accuracy, robustness, and cybersecurity through rigorous testing before deployment [21]
- CSA AI Controls Matrix: Specifies 243 controls across 18 security domains, many of which require structured testing activities [22]
These aren’t optional best practices. They’re becoming regulatory requirements. If you haven’t implemented structured teaming, you’re moving toward non-compliance.
Integration Strategy: Building Your Teaming Program
Here’s how I’d approach it:
Phase 1: Establish Governance (White Team) - Define who makes decisions. What’s the scope of testing? What does success look like?
Phase 2: Build Foundational Teams - Start with blue team capabilities. Defensive infrastructure and monitoring. Simultaneously, establish yellow teams to analyze risks.
Phase 3: Introduce Red Testing - Once blue team foundations exist, introduce red team testing against high-risk systems. Start with focused testing on specific concerns.
Phase 4: Establish Feedback Loops (Purple Team) - Ensure findings drive actual improvements. Immediate re-testing and validation.
Phase 5: Embed in Development (Orange and Green Teams) - Gradually integrate security into development workflows. Prevent vulnerabilities from being built in the first place.
Phase 6: Establish Continuous Monitoring - Monitor production systems for signs of degradation, drift, or misuse. This isn’t a one-time activity. It’s an ongoing operational requirement.
Conclusion: Teaming as Operational Necessity
Teaming in AI represents a fundamental shift. You’re moving from treating security as a checkpoint to embedding it as a continuous operational practice. If you deploy AI systems without structured teaming, you’re gambling. You’re hoping you won’t encounter the vulnerabilities that teams working elsewhere have already discovered.
The research is unambiguous: comprehensive teaming detects 92% of vulnerabilities. It reduces the cost of fixing issues by 78%. Every team type serves a distinct purpose. Missing any creates a specific category of blindness.
The regulatory landscape is evolving toward mandatory teaming. What’s now a best practice will soon be a legal requirement. If you build teaming capabilities today, you position yourself for compliant, resilient AI deployments. If you wait? You face a choice: implement teaming voluntarily or be forced to implement it reactively after public failures damage your reputation and create legal liability.
The future of AI safety depends not on individual brilliance but on structured collaboration. People thinking like attackers, defenders, managers, developers, and governance leaders. Teaming in AI isn’t a luxury. It’s how responsible AI organizations operate.
Key Takeaways
-
Teaming integrates diverse expertise: Red teams attack, blue teams defend, purple teams coordinate, orange teams educate, yellow teams analyze risk, green teams embed security, white teams govern, and gray teams assess insider threats.
-
Testing timing matters: Conduct red team testing before widespread internal usage, in production-like staging environments, at every model update, and continuously in production.
-
The cost of skipping teaming is quantifiable: 37% more vulnerabilities go undetected, 97% more time is required for manual testing, and 30% of projects are abandoned due to inadequate testing [2][5][16].
-
Teaming is becoming mandatory: NIST frameworks, Executive Orders, and regulatory requirements increasingly mandate structured testing.
-
Single-team approaches fail: Organizations need all team types working in coordination. Red teams alone miss business impact; blue teams alone can’t anticipate novel attacks; without governance, efforts become chaotic.
Sources
[1] Red Team and Blue Team Tactics in Modern Cybersecurity - Abnormal Security
[2] Red Teaming Your AI Before Attackers Do - Palo Alto Networks
[3] AI Red-Teaming Design: Threat Models and Tools - CSET Georgetown
[4] Why we should regulate AI before development - CFG
[5] Automated AI red teaming is critical to securing customer-facing GenAI chatbots - Fuelix
[6] Red Team vs Blue Team: Cybersecurity Roles Explained - FireCompass
[7] What is Model Drift? Types & 4 Ways to Overcome in 2026 - AIMultiple
[8] What is a Purple Team in Cybersecurity? - SentinelOne
[9] Red vs Blue vs Purple vs Orange vs Yellow vs Green vs White - Briskinfosec
[10] What is the Cybersecurity Color Wheel Model? Explained - CyberSics
[11] CyberSec Colour Team Structure - LinkedIn
[12] Understanding Cybersecurity Teams - IT Minister
[13] AI models can be dangerous before public deployment - METR
[14] 7 stages of ML model development - Lumenalta
[15] Red teaming in AI: A trust and safety imperative - Everest Group
[16] AI Implementation Failures in Real-World Deployments - Schellman
[18] The physical AI deployment gap - a16z
[20] AI Risk Management Framework - NIST
[21] The Future of AI Red Teaming: Challenges, Trends, and What’s Next - AyaData
[22] A Look at New AI Control Frameworks from NIST & CSA - Cloud Security Alliance
Views expressed are my own and do not represent my employer. External links open in a new tab and are not my responsibility.
Related Posts: For more on AI security and governance, see:
- AI Governance in Enterprise: Beyond Compliance Theater - Practical governance frameworks
- Securing RAG Systems - RAG-specific vulnerabilities and defenses
- The OWASP Top 10 for LLMs - Production security implementations
Last updated: January 2026
Discussion
Have thoughts or questions? Join the discussion on GitHub. View all discussions