What Happens When You Call an LLM API
Your prompt travels through 7 infrastructure layers before a single token comes back. A plain-language walkthrough of API gateways, tokenization, prefill, decode, post-processing, billing, and the network physics underneath.
When you send a request to an LLM API, the answer can arrive fast enough to feel instant.
That speed hides a lot of machinery.
Your request crosses the public internet, hits the provider’s edge, gets authenticated, tokenized, routed to a model server, processed on GPUs, filtered, billed, and turned back into text before it comes back to you.
Most of that time is not spent “traveling through the internet.” It is spent inside the provider’s infrastructure doing compute and queuing work that users never see.
This post explains that path in plain language.
It also answers a question that comes up often: if data moves close to the speed of light, why does an LLM response still take hundreds of milliseconds or more?
The Short Version
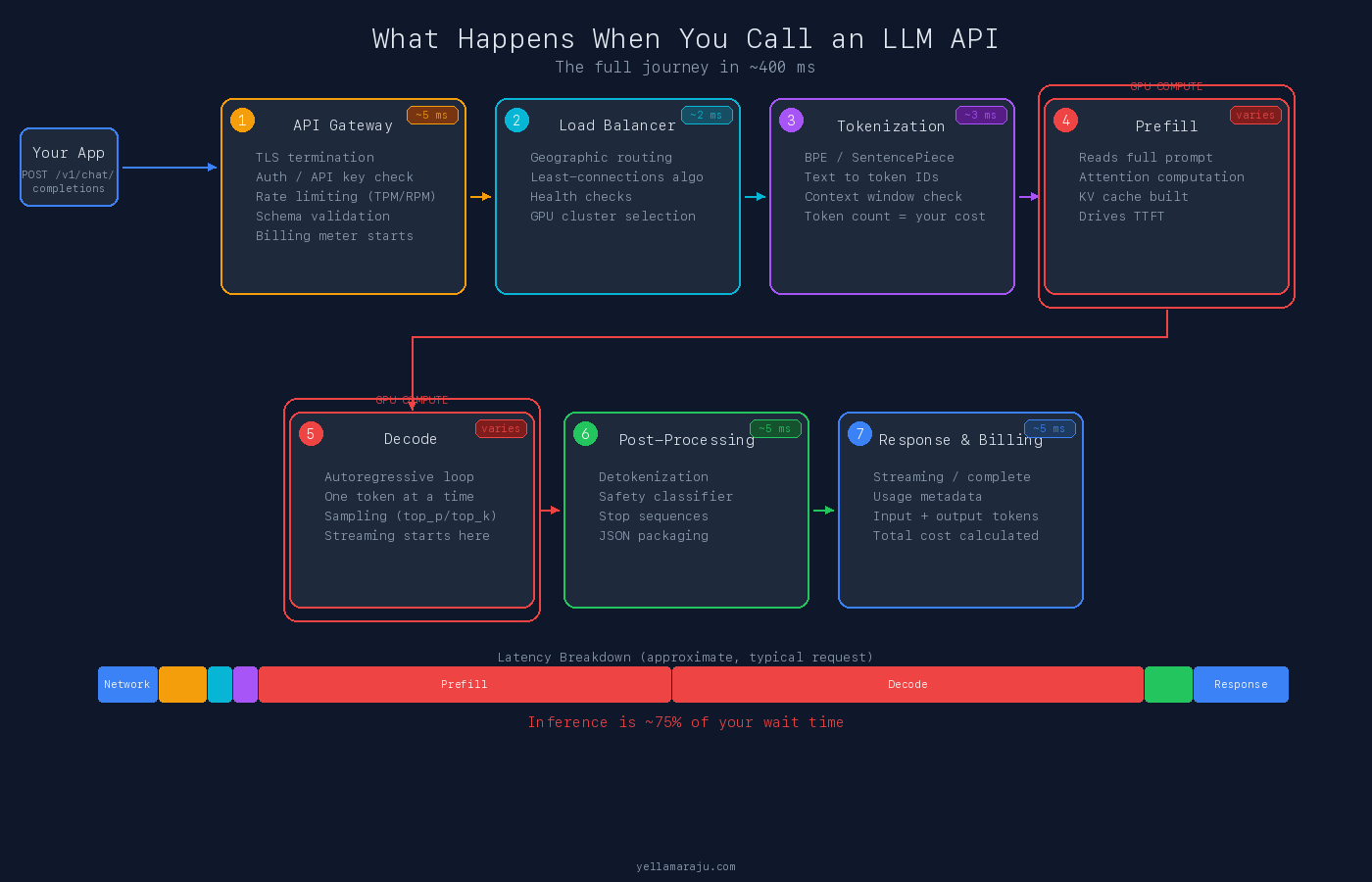
A typical LLM API request goes through seven broad stages:
- API gateway
- Internal routing and load balancing
- Tokenization
- Prefill, where the model reads the full prompt
- Decode, where the model generates output tokens
- Post-processing and safety checks
- Billing, packaging, and response delivery
The network matters. But for most real requests, the biggest delay is not the trip from your laptop to the provider. It is the work required to run the model.
A compact visual summary of this full lifecycle was recently shared by Brij Kishore Pandey on X:
The rest of this post walks through each stage in detail.
1. The Request Reaches the API Gateway
The first visible hop is the provider’s API gateway.
This is where the platform does the boring but necessary work:
- Terminate TLS
- Validate your API key
- Apply rate limits and quota checks
- Validate the request schema
- Attach request metadata for logging, tracing, and billing
This part is usually quick.
It is also where many requests fail early. A malformed payload, invalid key, or quota problem is often rejected here without ever reaching the model.
An LLM call is not just “prompt in, text out.” It is still an HTTP request passing through standard distributed systems layers.
2. The Platform Routes the Request Internally
Once admitted, the request is routed inside the provider’s network.
That routing layer decides where the work should run:
- Which region or data center should handle it
- Which model cluster has capacity
- Whether the request should go to a general-purpose model, a smaller low-latency model, or a specialized endpoint
- Whether it can be batched efficiently with other requests
Users often imagine that their prompt goes to a single giant machine. That is not how modern inference platforms work.
Requests are distributed across fleets of machines, and large models are often spread across multiple GPUs or multiple hosts.

The provider is managing two things at the same time:
- Quality of service for you
- Throughput and utilization for itself
Those goals are related, but not identical.
3. The Text Gets Tokenized
Before the model can do anything useful, the text must be converted into tokens.
A model does not read words the way a person does. It reads integer token IDs produced by a tokenizer such as BPE or SentencePiece.
"Hello world" → [15339, 1917]
That tokenization step matters for three reasons:
- Pricing is based on tokens
- Context limits are based on tokens
- Inference cost grows with token count
This is also where developers often misread performance. A prompt that “does not look that long” in plain English can still expand into a large token count once formatting, code, JSON, tool schemas, and conversation history are included.
The model never sees your prompt as a neat paragraph. It sees a long stream of token IDs.
Each token is roughly 4 characters. Input tokens are billed per 1K. Different providers use different tokenizers, so the same prompt can produce different token counts across APIs.
4. Prefill Is Where the Model Reads the Prompt
This is the first heavy compute stage.
During prefill, the model processes the entire input context and builds the internal state needed for generation. In transformer systems, this includes computing attention over the prompt and constructing the key-value (KV) cache used for later decoding.
This is why long prompts hurt time-to-first-token (TTFT). The model has to read the whole thing before it can start producing the answer.
If you send:
- A large system prompt
- A long conversation history
- Tool definitions
- Retrieved documents
- Structured examples
you are increasing the amount of prefill work before generation even begins.
This is one reason prompt design affects latency as much as it affects quality.
5. Decode Is Where the Model Generates Tokens
After prefill, the model moves into decode.
This is the stage most people picture when they think about inference. The model generates one token at a time, autoregressively. Each new token depends on the tokens that came before it.
That means output generation is inherently sequential in a way that prompt ingestion is not.
This is why long outputs can feel slow even after the first token appears. The platform is not “holding back” the answer. It is computing each next token, sampling from a probability distribution, updating state, and repeating that loop until it hits a stop condition.
Streaming makes this feel faster because the provider returns tokens as they are generated. That improves perceived latency. It does not remove the underlying decode cost.

6. This Work Runs on Expensive, Specialized Hardware
The middle of the request path is where the real cost lives.
Large-model inference runs on accelerators like NVIDIA A100 and H100 GPUs, often with large pools of high-bandwidth memory and high-speed interconnects between devices. The H100 SXM variant ships with 80 GB of HBM3 memory and 3.35 TB/s of memory bandwidth, connected via NVLink at up to 900 GB/s [1].
For smaller models, one accelerator may be enough. For frontier-scale models, the work may be split across multiple GPUs because the weights, KV cache, and runtime memory demands are too large for a single device.
This is also why inference engineering matters so much.
The basic transformer attention mechanism is expensive in both memory and compute. Techniques like FlashAttention improved this by reducing unnecessary memory traffic and making better use of GPU hardware. FlashAttention-2 reported reaching 50 to 73 percent of theoretical maximum FLOPs/s on A100 GPUs, roughly a 2x speedup over the original FlashAttention [2].
The practical takeaway is simple: much of modern LLM performance comes not only from better models, but from better systems work around those models.
7. Post-Processing Happens After Generation
Once the model has finished generating, the provider still has a few more steps to run:
- Convert token IDs back into text (detokenization)
- Apply output formatting
- Run policy or safety checks
- Detect stop sequences or truncation conditions
- Package the result into JSON or a streaming event format
- Record usage metadata
This part is usually not the dominant share of latency, but it is still part of the path.
Every major provider runs content moderation at this stage. If the safety classifier flags your output, the response can be stopped or modified. The finish reason will tell you why: stop, length, or content_filter.
8. Billing Happens at the End, but Cost Starts Much Earlier
From the user’s point of view, billing appears at the end of the request. From the platform’s point of view, cost begins the moment the request is accepted and resources are allocated.
Providers typically meter:
- Input tokens
- Output tokens
- Sometimes cached versus uncached input tokens
Output tokens are usually 3 to 5x more expensive than input tokens per 1K.
This is where prompt caching can matter. OpenAI’s prompt caching feature reduces latency by up to 80 percent and input token costs by up to 90 percent for prompts longer than 1,024 tokens. Cached prefixes are evicted after 5 to 10 minutes of inactivity [3].
That does not make inference free. It does reduce repeated prompt overhead in workloads with large static prefixes, like assistants with long system prompts or repeated tool instructions.
Why Distance Still Matters
Even though inference dominates most user-visible latency, network physics still sets a floor.
Signals in optical fiber do not travel at the speed of light in vacuum. The refractive index of glass fiber is roughly 1.5, which means light travels at about 200,000 km/s in fiber, around 35 percent slower than in vacuum [4]. A useful rule of thumb is about 5 microseconds per kilometer one way.
That means long-haul routes accumulate delay quickly, even before you account for routers, switches, and queuing.
But the more important point is that real internet paths are rarely straight.
Academic work on long-haul US fiber infrastructure has shown that conduit lengths are often substantially longer than simple line-of-sight distance. Bozkurt et al. found that measured internet latency is often much worse than the ideal lower bound predicted by geography alone, with the ratio between observed and theoretical minimum latency varying widely across US city pairs [5]. Earlier work by Durairajan et al. mapped long-haul fiber conduits across the contiguous US, documenting how fiber routes follow railroad rights-of-way, highway corridors, and other non-geographic paths [6].

That extra delay comes from:
- Circuitous fiber routes
- Slack loops left for maintenance
- Optical layer overhead
- Routing policy choices
- Congestion and queuing
The path between two cities is not a ruler line on a map. It is shaped by business decisions, legacy infrastructure, and real-world physics.
Why the Internet Is Usually Not the Main Bottleneck
If you are sending a short request to a provider in the same broad region, the public internet hop may only be a modest fraction of end-to-end latency.
The more expensive part is often:
- Waiting for the request to enter the right queue
- Processing a large prompt during prefill
- Generating many output tokens during decode
In other words: physics gives you a baseline, but compute gives you the bill.
That is why shrinking a prompt often helps latency more than obsessing over a few milliseconds of network distance.
What You Can Actually Control
You cannot change the speed of light. You can change a lot of other things.

1. Keep prompts smaller
Long prompts increase prefill time, token cost, and memory pressure. If the model does not need a paragraph, do not send a paragraph.
2. Ask for shorter outputs
Long outputs increase decode time because generation is token-by-token. If your UI only needs a concise answer, ask for one.
3. Choose the right model
A smaller model with lower latency is often the better product choice for classification, routing, extraction, and light summarization. Do not use your largest model for every request by default.
4. Use streaming when UX matters
Streaming does not reduce total generation cost, but it improves perceived speed. For chat, that often matters more than absolute completion time.
5. Put users near the region that serves them
If your traffic is concentrated in one geography, avoid adding unnecessary transcontinental hops. Distance still matters at the margins.
6. Reuse prompt prefixes when possible
Prompt caching and repeated static prefixes can lower both latency and cost in some workloads.
What This Means for Engineers
The hidden path behind an LLM API call matters because it changes how you design systems.
If you think the latency is “just network,” you will optimize the wrong layer.
If you think the cost is “just model pricing,” you will miss the effect of prompt size, output length, retries, and batching.
If you think streaming means the model is done faster, you will confuse perceived latency with total compute time.
The real engineering lesson is that an LLM call is not a magic function. It is a distributed systems pipeline wrapped around an expensive autoregressive compute loop.
You type a prompt. About 400 ms and 14 infrastructure layers later, you get your answer. Inference is roughly 75 percent of your wait time. The network is the floor. Compute is the bill.
Final Takeaways
- Most of the visible delay in an LLM API call happens inside the provider’s infrastructure, not on the open internet.
- Long prompts mostly hurt prefill. Long outputs mostly hurt decode.
- Network physics sets a floor, but real-world routing makes that floor messier than simple geographic distance suggests.
- GPU memory, batching, and inference kernels matter because the model is doing heavy numerical work, not simple string processing.
- The most useful latency levers for application builders are usually prompt size, output length, model choice, streaming strategy, and regional placement.
When you press send, your request does travel far. But the bigger story is what happens after it arrives. That is where the milliseconds, the money, and the engineering tradeoffs live.
References
- NVIDIA H100 Tensor Core GPU Datasheet
- FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning (Tri Dao, 2023)
- OpenAI Prompt Caching
- Speed of light in optical fiber, refractive index ~1.5
- Dissecting Latency in the Internet’s Fiber Infrastructure (Bozkurt et al., 2018)
- InterTubes: A Study of the US Long-haul Fiber-optic Infrastructure (Durairajan et al., 2015)
Views expressed are my own and do not represent my employer. External links open in a new tab and are not my responsibility.
Discussion
Have thoughts or questions? Join the discussion on GitHub. View all discussions