Why Your AI Agent Fails: It's Not the Model, It's the Harness
Most AI agents fail not because the model is wrong, but because the infrastructure around it is missing. This is a beginner-to-expert guide on what an agent harness is, how it works, and why it is the most overlooked layer in AI systems.
It was 11:47 PM when Arjun’s phone lit up.
The support bot his team had shipped three weeks ago had started looping. Customers were getting the same refund rejection message six times in a row. Some were getting contradictory answers — first told the policy allowed returns, then told it did not — within the same conversation. The model was GPT-4o. It had passed every evaluation. The prompts were reviewed by two senior engineers. The product demo had gone perfectly.
And yet, here they were.
This story is not unusual. In 2025, Gartner predicted that over 40% of agentic AI projects would be cancelled by end of 2027 — not because the underlying models were wrong, but because of escalating costs, unclear reliability, and inadequate risk controls.1 A separate analysis found that fewer than 1 in 8 enterprise agent initiatives actually reach stable production.2
The engineers building these systems are not incompetent. The models powering them are genuinely capable. What is almost always missing is the layer between the model and the world.
That layer has a name: the agent harness.
Video explainer — Watch a 30-second animated walkthrough of the full harness architecture below, then read on for the deep-dive.
Chapter 1: You Didn’t Build a System. You Wrote a Prompt.
Let’s start at the beginning. When most people build an AI agent, here is what the architecture looks like in reality:
User Input → LLM → Output
Maybe there are a few tools attached. Maybe a system prompt that is 800 words long. Maybe a temperature=0.2 setting someone read was more reliable.
This is not a system. This is a prompt with ambition.
The problem is not that prompts are bad. Prompts are essential. The problem is that prompts are unenforceable. You ask the model to always check inventory before confirming an order. You cannot make it. You tell it never to quote a price without checking the database. It will, when the context window gets crowded and the database tool call gets deprioritised.
An LLM responds to instructions. It does not obey them. The difference matters enormously in production.
Arjun’s team had a great prompt. They had a terrible system. The model would sometimes call the same tool three times because nothing in the loop was tracking which tools had already been used. There was no validator checking whether the output contradicted something said earlier in the conversation. There was no state management ensuring the agent remembered what had happened two messages ago when the context window was near its limit.
What they needed — what every production AI system needs — is a harness.
Chapter 2: What Is an Agent Harness?
The simplest definition comes from the engineering community: a harness is everything in an AI agent except the model itself.3
If the model is the brain, the harness is the body — the nervous system, the senses, the memory, the hands that execute actions, and the conscience that stops harmful ones.
More formally, Martin Fowler’s team at ThoughtWorks describes it as the complete set of feedforward controls (guides that prevent bad output before it happens) and feedback controls (sensors that observe and correct after the model acts).4
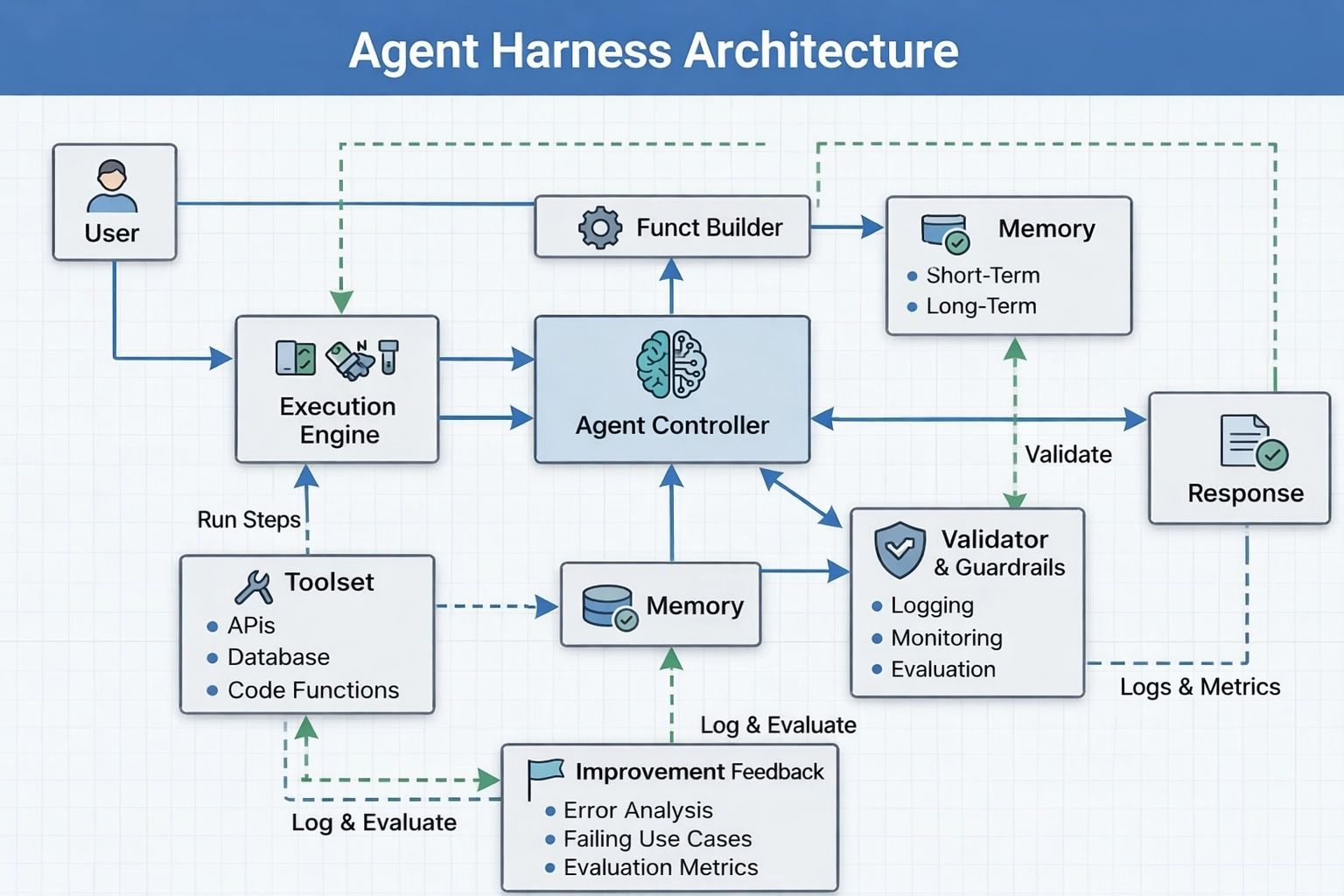
Here is how it maps to engineering components you actually build:
This is not a marketing diagram. Every one of these boxes is code you have to write, decisions you have to make, failures you have to handle.
Chapter 3: The Six Pillars of an Agent Harness
Pillar 1 — Orchestration: The Controller
The Agent Controller is the conductor of the orchestra. It receives the user’s intent, decides which tools or sub-agents to invoke, sequences operations, and maintains the high-level goal across multiple steps.
In simple agents, this might be a ReAct loop: Reason → Act → Observe → Reason again. In complex systems, it becomes a full orchestrator-worker architecture where the controller delegates specific tasks to specialised sub-agents, each with isolated context windows.5
The controller is responsible for one critical thing: keeping the agent on task. Without it, agents drift. They hallucinate tool names. They solve the wrong sub-problem. They get stuck in loops.
Pillar 2 — Tool Orchestration: The Execution Engine
Tools are how agents affect the world — querying databases, calling APIs, running code, writing files. The Execution Engine manages this surface.
This is not just a list of function definitions. Production harnesses define which tools are available at each step, validate tool calls before executing them, sandbox dangerous operations, and return sanitised, structured results back to the model.6
Vercel removed 80% of the tools available to their coding agent and achieved better results. More tools does not mean better agents — it means a more confused model with a faster path to failure.7
Pillar 3 — Memory: Short-Term and Long-Term
LLMs are stateless. Every request is, to the model, the beginning of time. The harness changes this.
Production harnesses manage three layers of memory:6
- Working context — what the model sees right now, carefully curated for relevance
- Session state — durable logs of what has happened in this task, persisted to a database so restarts do not lose progress
- Long-term memory — knowledge that persists across sessions: user preferences, past decisions, solved problems
The file system is memory. The database is memory. The context window is just the slice of memory the model can see in one moment. The harness decides what goes where.
Pillar 4 — Validation & Guardrails: The Validator
This is the piece almost every early-stage AI system skips, and the piece whose absence explains most production failures.
A Validator checks model outputs before they reach the user or trigger irreversible actions. It asks: Does this output contradict something we said five messages ago? Did the agent try to call a tool it does not have permission to use? Is this response structurally valid before it gets parsed downstream?
Production harnesses do not trust model output. They verify it.
Validators can be computational (run the code, check if the tests pass) or inferential (use a second model to judge the output). Computational validators are cheap and fast. Inferential validators are slower and more powerful. Production systems use both, applied at different points in the pipeline.4
Pillar 5 — Function / Tool Builder: Dynamic Capability
In advanced harnesses, tools are not static. The Function Builder constructs or modifies tool definitions at runtime based on what the task requires. Think of it as the harness telling the agent what it is allowed to do for this specific request — narrowing the action space to reduce risk and improve focus.
Pillar 6 — Improvement Feedback: The Learning Loop
This is the pillar most production systems add last, and the one that separates reliable systems from exceptional ones. Every interaction — every failure, every retry, every user correction — is a data point. The harness captures it.
Error analysis. Failing use cases. Evaluation metrics. These flow back into the system, eventually informing better prompts, better validators, and better tools. We will return to this in detail in Blog 2.
Chapter 4: Skill vs Harness — The Critical Distinction
Here is one of the most misunderstood distinctions in AI engineering, made clear:
| Skill | Harness | |
|---|---|---|
| Definition | What you ask the LLM to do | What your system enforces |
| Lives in | Prompts, instructions, context | Code, configuration, infrastructure |
| Reliability | Probabilistic | Deterministic |
| Examples | ”Always check inventory first” | A validator that blocks any response claiming availability without a database confirmation |
| Can be bypassed by the model? | Yes | No |
A skill is a request. A harness is a constraint.
The HumanLayer team describes it precisely: skills are progressive knowledge disclosure — the agent gets access to specific instructions or tools only when it needs them. The harness is the system that decides when it needs them and ensures the skill is applied correctly.8
When Arjun’s team told their model “always apologise before delivering bad news,” that was a skill. It worked 90% of the time. When a validator was added that detected any refund denial response and checked whether it contained an acknowledgement phrase before allowing delivery — that was a harness component. It worked 100% of the time.
The goal is not to eliminate skills. The goal is to stop relying on them for things that matter.
Chapter 5: What Actually Goes Wrong
Four failure modes bring down most production agents.
1. Relying on prompts for reliability Prompts set direction. They do not guarantee behaviour. A 1,200-word system prompt is not a harness. It is a very expensive suggestion.
2. No output validation The model returns plausible-looking structured data. Your downstream system parses it. Occasionally the structure is wrong. The parsing breaks. The user sees a 500 error. Without a validator, you find out from a customer complaint.
3. Poor context management As conversations grow, old context is pushed out. The agent “forgets” the original instructions. It forgets what tools it has already called. It starts contradicting earlier statements. Arjun’s looping bot was doing this — the refund instruction was so far back in context it effectively vanished.
4. Uncontrolled tool usage Tools with side effects — sending emails, writing to databases, calling external APIs — need explicit permission gating. Without it, agents do things they should not, at scale, automatically.
An agent that is 85% accurate on any single step will complete a 10-step task correctly only 20% of the time. Reliability compounds — or rather, failures compound. This is the mathematics that kills production agents.9
Chapter 6: Why This Matters at Enterprise Scale
Individual demos hide harness debt. Enterprise scale exposes it immediately.
When a solo developer uses an AI coding assistant, an occasional wrong answer is a minor annoyance. When a company routes 50,000 customer support interactions per day through an AI agent, a 3% failure rate is 1,500 broken experiences — every day.
Enterprise-grade harnesses address three concerns directly:
Reliability — Deterministic validation, retry logic, graceful degradation. The system handles failure modes, not just happy paths.
Cost control — Uncontrolled agents make unnecessary tool calls, generate excessive tokens, retry without limits. Harnesses implement budgets, caching, and early stopping. Without them, costs grow unpredictably.
Observability — You cannot improve what you cannot see. Every tool call, every model output, every validator decision should be logged. The harness is the natural place to instrument this.
Companies like Stripe are reportedly handling 1,300 AI-generated pull requests per week.10 That volume is only possible because the harness — the orchestration, validation, and tool management layer — is doing the heavy lifting of making the model’s output trustworthy enough to act on.
Models are becoming commodities. The harness is where the actual engineering advantage lives.7
Chapter 7: A Simple Harness in Practice
Here is a minimal but real harness pattern, without any framework, just Python:
import anthropic
import json
from typing import Any
def run_agent(user_message: str, tools: list[dict]) -> str:
client = anthropic.Anthropic()
messages = [{"role": "user", "content": user_message}]
# The agentic loop — this IS the orchestration layer
while True:
response = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=4096,
tools=tools,
messages=messages,
)
# Validation: check stop_reason before trusting output
if response.stop_reason == "end_turn":
final_text = next(
block.text for block in response.content
if hasattr(block, "text")
)
# Guardrail: validate output before returning
return validate_and_sanitize(final_text)
if response.stop_reason == "tool_use":
tool_calls = [b for b in response.content if b.type == "tool_use"]
tool_results = []
for call in tool_calls:
# Permission gate: check before executing
if not is_tool_permitted(call.name, call.input):
tool_results.append({
"type": "tool_result",
"tool_use_id": call.id,
"content": "Permission denied for this operation.",
"is_error": True,
})
continue
result = execute_tool(call.name, call.input)
tool_results.append({
"type": "tool_result",
"tool_use_id": call.id,
"content": json.dumps(result),
})
# Update conversation state — this is memory management
messages.append({"role": "assistant", "content": response.content})
messages.append({"role": "user", "content": tool_results})
Notice what is happening here. The model generates output. The harness checks stop_reason before trusting it. Every tool call goes through is_tool_permitted before execution. The output goes through validate_and_sanitize before the user sees it. The conversation state is explicitly managed.
This is still a minimal harness. A production version adds logging, retry logic, cost tracking, context truncation management, and human-in-the-loop hooks. But the pattern — orchestrate, validate, control, observe — is the one that matters.
Ending: The System Behind the Intelligence
Arjun’s team fixed their bot. Not by switching to a better model. Not by rewriting the prompt. They added a state tracker that prevented duplicate tool calls. They added an output validator that caught contradictory statements. They added a simple context manager that summarised old conversation history before it fell out of the window.
Three engineering changes. Two days of work. The looping stopped.
The model had been right all along. The harness had been missing.
But even a well-designed harness is not a permanent solution. Systems degrade. User behaviour changes. Edge cases accumulate. The model that was accurate six months ago slowly becomes less accurate — not because the model changed, but because the world did.
The real engineering challenge begins after deployment. And that is exactly where Blog 2 picks up.
Key Takeaways
- An agent harness is everything in an AI agent except the model itself — orchestration, tools, memory, validation, and guardrails
- Skills are what you ask the LLM to do. Harness is what your system enforces. Skills are probabilistic. Harnesses are deterministic.
- The six pillars: Controller, Execution Engine, Memory, Validator, Function Builder, Improvement Feedback
- Most production agent failures trace back to missing harness components — not model capability
- At enterprise scale, reliability, cost control, and observability are not optional — they require explicit harness engineering
- Models are becoming commodities. The harness is where the actual engineering advantage lives.
Footnotes
-
Gartner, “Gartner Predicts Over 40% of Agentic AI Projects Will Be Canceled by End of 2027,” June 2025. https://www.gartner.com/en/newsroom/press-releases/2025-06-25-gartner-predicts-over-40-percent-of-agentic-ai-projects-will-be-canceled-by-end-of-2027 ↩
-
Digital Applied, “Why 88% of AI Agents Fail Production,” 2025. https://www.digitalapplied.com/blog/88-percent-ai-agents-never-reach-production-failure-framework ↩
-
Parallel AI, “What is an agent harness in the context of large-language models?” https://parallel.ai/articles/what-is-an-agent-harness ↩
-
Martin Fowler / ThoughtWorks, “Harness engineering for coding agents.” https://martinfowler.com/articles/exploring-gen-ai/harness-engineering.html ↩ ↩2
-
Decoding AI, “Agentic Harness Engineering: LLMs as the New OS.” https://www.decodingai.com/p/agentic-harness-engineering ↩
-
Firecrawl, “What Is an Agent Harness? The Infrastructure That Makes AI Agents Actually Work.” https://www.firecrawl.dev/blog/what-is-an-agent-harness ↩ ↩2
-
Aakash Gupta, “2025 Was Agents. 2026 Is Agent Harnesses.” Medium, 2026. https://aakashgupta.medium.com/2025-was-agents-2026-is-agent-harnesses-heres-why-that-changes-everything-073e9877655e ↩ ↩2
-
HumanLayer, “Skill Issue: Harness Engineering for Coding Agents.” https://www.humanlayer.dev/blog/skill-issue-harness-engineering-for-coding-agents ↩
-
Towards Data Science, “The Math That’s Killing Your AI Agent.” https://towardsdatascience.com/the-math-thats-killing-your-ai-agent/ ↩
-
MindStudio, “What Is an AI Agent Harness? The Architecture Behind Stripe’s 1,300 Weekly AI Pull Requests.” https://www.mindstudio.ai/blog/what-is-ai-agent-harness-stripe-minions ↩
Discussion
Have thoughts or questions? Join the discussion on GitHub. View all discussions