From Agent Harness to Self-Improving AI Systems
A solid harness makes your agent reliable at launch. A self-improving system keeps it reliable over time. This is the engineering discipline that separates production AI from drifting AI — failure mining, eval generation, regression gating, and the feedback loop architecture that ties it all together.
You built the harness. The agent is in production. It works.
For three months, everything is fine. Then, slowly, it is not.
The support agent that handled 94% of queries in January is handling 81% in April. Not because the model changed. Not because the harness broke. Because the world changed — new product features, new edge cases in user language, new combinations of inputs that the harness was never trained to expect. The evaluation suite you ran before launch no longer reflects the queries coming in today.
This is not a bug. This is the natural state of deployed AI systems.
AI systems do not stay correct. They drift. The harness keeps them reliable at launch. The feedback loop keeps them reliable over time.
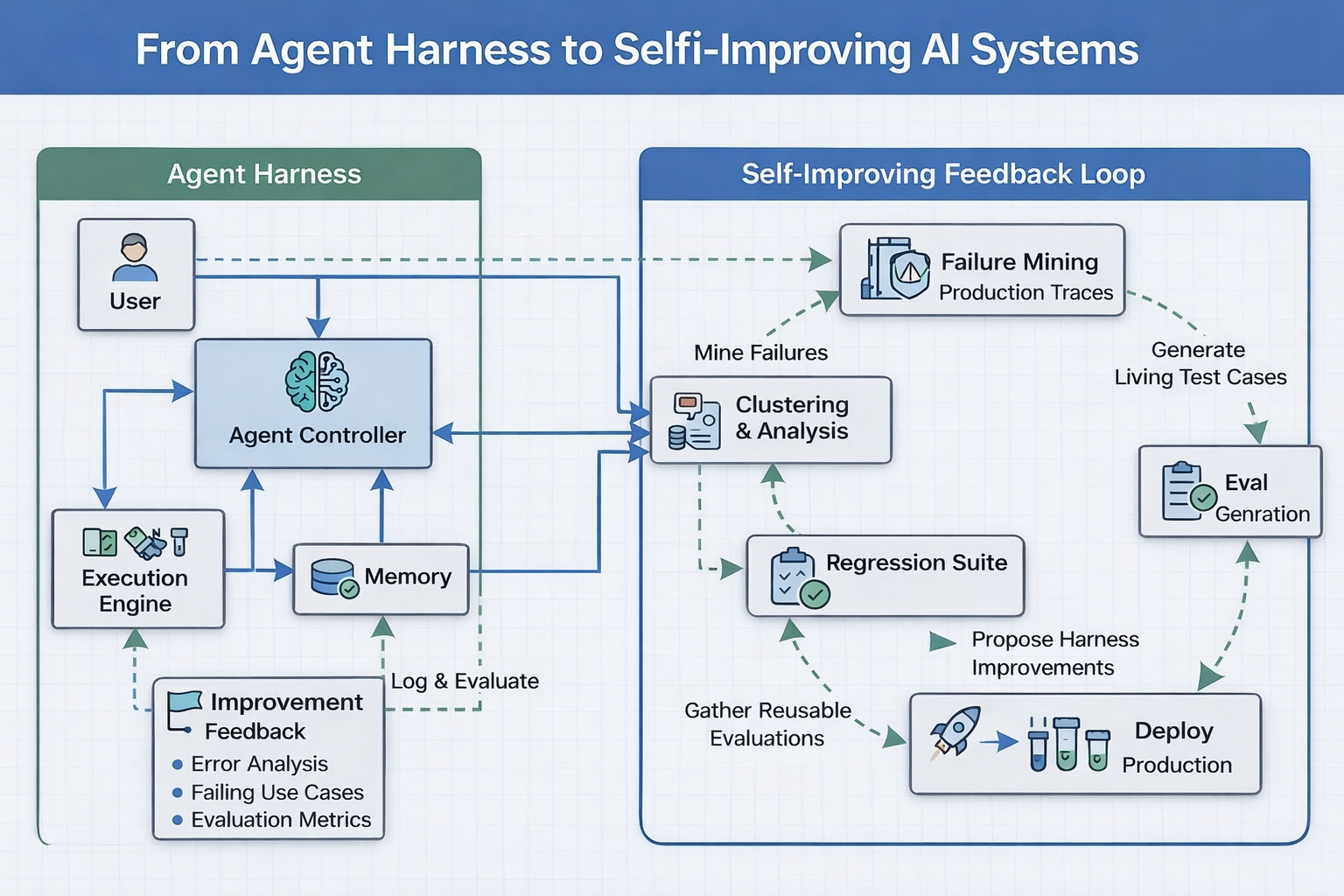
This post is about what comes after the harness: the engineering discipline of building AI systems that improve from their own failures. If Blog 1 was about making your system reliable, this is about keeping it reliable — indefinitely.
Video explainer — The 40-second animated walkthrough below covers the complete feedback loop: Drift → Failure Mining → Clustering → Evals → Regression Gate → Deploy. Watch it first, then read the full breakdown.
Part 1: What Drift Actually Looks Like
Before we discuss solutions, it is worth being precise about the problem. “AI drift” is used loosely. It actually describes three distinct phenomena, each requiring a different response.
Distributional shift — The inputs arriving in production no longer resemble the inputs you tested on. Users phrase things differently than you expected. New product features introduce query types that did not exist at launch. The agent’s behaviour degrades because it was calibrated on a different distribution.
Edge case accumulation — Every week, new edge cases emerge that your harness handles incorrectly. These are individually rare, but cumulatively significant. A single edge case represents a 0.1% failure rate. Fifty edge cases represent a 5% failure rate. Left unaddressed, they compound.
Regression from improvement — You fix a problem. In doing so, you inadvertently break something that was working. Without a comprehensive regression suite, you do not know this until users tell you.
An MIT report in 2025 identified what they called the “learning gap” in enterprise AI: projects stall because organisations do not know how to design AI systems that actually learn and adapt from production behaviour.1 The systems are built to launch, not to learn.
The question is not whether these things will happen. They will. The question is whether your system is designed to catch them, learn from them, and close the gap — automatically.
Part 2: The Self-Improving Feedback Loop
Here is the architecture that separates adaptive AI systems from static ones:

Each stage in this loop has a specific engineering job. Let us go through them precisely.
Part 3: Failure Mining — Turning Production Into Signal
The first principle of self-improving systems: every failure is an asset.
This is not a motivational sentiment. It is an engineering stance. Every production failure contains information about a gap between what your system expects and what the world delivers. The question is whether you capture that information or let it evaporate.
What to log
Logging “the agent failed” is insufficient. A useful failure log captures:
- The exact input that triggered the failure
- The full reasoning trace (every tool call, every intermediate output)
- The final output and why it was wrong (user correction, validation failure, explicit error, low confidence score)
- The context state at failure time (conversation history, memory state, tool availability)
This is not just for debugging. It is the raw material for everything downstream.
Sources of failure signal
Not all failures are explicit. Production signals come from multiple layers:
| Signal Type | Source | Reliability |
|---|---|---|
| Hard errors | Validation failures, exceptions | High — deterministic |
| User corrections | Thumbs down, re-asks, escalations | High — direct signal |
| Implicit dissatisfaction | Conversation abandonment, re-phrasing | Medium — requires inference |
| Latent quality issues | LLM-as-judge scoring on sampled outputs | Medium — requires calibration |
| Business metric divergence | Conversion drop, support volume increase | Low signal-to-noise, high stakes |
A mature failure mining system listens to all of these, with different weights and handling for each.
from dataclasses import dataclass
from enum import Enum
from datetime import datetime
class FailureSignal(Enum):
HARD_ERROR = "hard_error" # Validator rejection, exception
USER_CORRECTION = "user_correction" # Explicit thumbs down, re-ask
ABANDONMENT = "abandonment" # User left without resolution
LLM_JUDGE_FAIL = "llm_judge_fail" # Automated quality scoring failure
BUSINESS_METRIC = "business_metric" # Downstream KPI degradation
@dataclass
class FailureTrace:
trace_id: str
timestamp: datetime
signal_type: FailureSignal
input_payload: dict
reasoning_steps: list[dict] # Full tool call chain
final_output: str
failure_reason: str
context_snapshot: dict # Memory state at failure time
severity: float # 0.0 to 1.0
def mine_failures(
traces: list[FailureTrace],
signal_weights: dict[FailureSignal, float],
) -> list[FailureTrace]:
"""
Filter and rank failures by weighted signal strength.
High-severity hard errors surface immediately.
Patterns of implicit dissatisfaction surface over time.
"""
scored = [
(trace, trace.severity * signal_weights[trace.signal_type])
for trace in traces
]
return [t for t, _ in sorted(scored, key=lambda x: -x[1])]
Part 4: Clustering & Analysis — Finding the Pattern in the Noise
A single failure is noise. A cluster of similar failures is a signal.
Clustering is the step that transforms a pile of individual failure logs into actionable insight. The goal is to identify failure modes — recurring patterns that share a common root cause — so that fixing one representative case fixes the whole class.
What clustering actually does
You are not clustering by input similarity alone. You are clustering by failure mode — the combination of input type, context state, and failure mechanism that produces the error.
from sklearn.cluster import DBSCAN
import numpy as np
def cluster_failures(
failure_traces: list[FailureTrace],
embedding_fn,
min_cluster_size: int = 3,
) -> dict[int, list[FailureTrace]]:
"""
Embed failure traces by (input + failure_reason + context_type),
then cluster with DBSCAN for density-based grouping.
Small, tight clusters = systemic failure modes.
Noise points = genuinely one-off incidents.
"""
embeddings = np.array([
embedding_fn(
f"{t.input_payload} | {t.failure_reason} | {list(t.context_snapshot.keys())}"
)
for t in failure_traces
])
clusterer = DBSCAN(eps=0.3, min_samples=min_cluster_size)
labels = clusterer.fit_predict(embeddings)
clusters: dict[int, list[FailureTrace]] = {}
for trace, label in zip(failure_traces, labels):
if label == -1:
continue # Noise — handle individually
clusters.setdefault(label, []).append(trace)
return clusters
Once clusters are identified, a second pass uses an LLM to generate a natural-language description of each failure mode — what the cluster is, why it fails, and what the fix might look like. This is the output that goes to engineers and into the eval generation step.
Bloomberg engineers achieved a 70% reduction in regression cycle time by clustering flaky failures by root cause and applying targeted fixes per cluster, rather than treating each failure individually.2
Part 5: Eval Generation — Building a Living Test Suite
This is the conceptual centre of the self-improving system: every production failure becomes a test case.
Traditional test suites are written before deployment, reflecting what engineers imagined could go wrong. A living eval suite grows from what actually went wrong in production, continuously.
The three-layer eval structure
Layer 1: Deterministic evals
→ Input/output pairs where the correct answer is unambiguous
→ Generated directly from hard-error traces
→ Run on every code change (seconds to complete)
Layer 2: Semantic evals
→ Cases where correctness requires judgment
→ LLM-as-judge scoring against rubrics derived from failure analysis
→ Run on significant changes (minutes to complete)
Layer 3: Behavioral evals
→ End-to-end task completion on realistic scenarios
→ Derived from clustered failure modes and business metric regressions
→ Run on releases (hours to complete)
Automated eval generation
Given a clustered failure mode with representative traces, an LLM generates a structured eval:
def generate_eval_from_cluster(
cluster_description: str,
representative_traces: list[FailureTrace],
llm_client,
) -> dict:
"""
Given a failure cluster, generate:
1. A minimal reproduction case
2. The expected correct behaviour
3. A rubric for automated scoring
4. Tags for categorisation
"""
prompt = f"""
You are generating an evaluation case for an AI agent regression suite.
Failure Mode: {cluster_description}
Representative failures:
{[t.input_payload for t in representative_traces[:3]]}
Generate a JSON eval case with:
- id: unique identifier
- input: minimal input that reproduces the failure
- expected_behaviour: what the agent should do correctly
- failure_indicator: what the agent does when this eval fails
- scoring_rubric: list of criteria for LLM-as-judge evaluation
- tags: list of failure category tags
- severity: 1-5 scale
"""
response = llm_client.generate(prompt)
return parse_eval_json(response)
This is what “failures become assets” means in engineering terms. The failure trace becomes the test case. The test case becomes part of the regression suite. The system gets tested against its own failure history on every subsequent deployment.
Part 6: The Regression Suite — The System Cannot Forget
The regression suite is the institutional memory of your system’s failure history.
A new feature ships. It improves performance on new cases by 3%. But it breaks handling on five edge cases the team fixed three months ago — edge cases the model has now “forgotten” because the prompts changed and the context management shifted.
Without a regression suite, you find this out from users. With one, you find it in CI before the deployment is approved.
The regression gate principle
The regression gate enforces one rule: the system cannot be deployed if it has regressed on any previously solved problem.
This sounds obvious. It is almost never implemented. Most teams treat evaluation as a pre-launch activity, not a continuous gate. They run evals once, feel good, and deploy whenever tests pass. The regression suite changes this — it is a continuously growing body of evidence about what the system is supposed to handle, and no deployment passes without satisfying it.
def regression_gate(
eval_results: list[EvalResult],
baseline_results: list[EvalResult],
block_on_regression: bool = True,
) -> GateDecision:
"""
Compare current eval results against baseline.
Any eval that passed before and fails now is a regression.
Regressions block deployment unless explicitly overridden.
"""
regressions = [
r for r in eval_results
if r.eval_id in {b.eval_id for b in baseline_results if b.passed}
and not r.passed
]
if regressions and block_on_regression:
return GateDecision(
approved=False,
regressions=regressions,
message=f"Blocked: {len(regressions)} regression(s) detected. "
f"Fix before deploying."
)
# New failures get added to the eval suite for next run
new_failures = [r for r in eval_results if not r.passed]
schedule_eval_generation(new_failures)
return GateDecision(approved=True, new_evals_queued=len(new_failures))
Part 7: Proposing Harness Improvements — Closing the Loop
The feedback loop completes when failure analysis drives changes to the harness itself — not just to prompts or context, but to the structural components that govern how the agent behaves.
What kinds of improvements emerge from failure analysis?
| Failure Pattern | Harness Improvement |
|---|---|
| Agent calls same tool 3+ times before stopping | Add tool call deduplication to the execution engine |
| Outputs contradict earlier conversation | Add conversation consistency validator |
| Agent ignores instructions when context is long | Add explicit context management for instruction pinning |
| Permission errors on sensitive operations | Add granular permission scoping to tool registry |
| Hallucinated tool names | Add tool name validation before execution |
| Cost spikes from retry loops | Add retry budget and circuit breaker |
This is the distinction that matters: improvements derived from production failures are better than improvements derived from engineering intuition. They are targeted at real problems, not imagined ones.
SICA (Self-Improving Coding Agent) validates every proposed self-edit against benchmarks — success rate, runtime, cost — before adopting the change. Only improvements that actually improve performance get merged. This principle applies equally to harness changes: verify before shipping.3
Part 8: What Is Actually Hard
This architecture is compelling on paper. In practice, there are four problems that are genuinely difficult, and they should be named directly.
1. Defining good evals is hard
An eval suite is only as useful as its evals are meaningful. Writing evals that reliably distinguish correct from incorrect behaviour — especially for open-ended tasks where “correct” is subjective — is a design problem that no amount of automation resolves. LLM-as-judge scoring is powerful but requires careful calibration. Judges drift. They have their own biases. Running them at scale is expensive.
2. Avoiding overfitting to the eval suite
Once a system is optimised against a growing eval suite, there is a real risk of overfitting — achieving high eval scores by memorising failure patterns rather than generalising correctly. This is analogous to Goodhart’s Law: when a measure becomes a target, it ceases to be a good measure. The eval suite should grow continuously from new production failures to prevent stagnation.
3. Controlling cost
Running semantic and behavioural evals at scale is not free. A suite of 5,000 LLM-evaluated cases, run on every deployment, can cost thousands of dollars per week. Production harnesses need cost-aware evaluation strategies: deterministic evals run on every commit, semantic evals run on significant changes, full behavioural suites run on releases.
4. Safety and oversight
Self-improving systems that can modify their own prompts, validators, or tool configurations introduce governance risk. Every change proposed by the improvement loop should pass through a human review gate or, at minimum, a strict automated safety check before deployment. Automated improvement without oversight is how systems develop unexpected and undesirable behaviours at scale.
Part 9: A Realistic Adoption Path
You do not build all of this at once. Here is a progression that is actually achievable:
Stage 1 — Manual evals (Week 1) Write 20-30 test cases from your initial evaluation. Run them manually before each deployment. This takes an afternoon and immediately catches gross regressions.
Stage 2 — Structured failure logging (Month 1) Add structured logging to your harness for every validation failure and user correction. Build a simple dashboard showing failure rates by type. This gives you the raw material for everything downstream.
Stage 3 — Failure triage and manual eval growth (Month 2-3) Review failure logs weekly. For any failure that recurs three or more times, write an eval case. Add it to the suite. Run the suite in CI. The suite grows from production reality, not engineering imagination.
Stage 4 — Automated clustering (Month 3-6) Add automated clustering to identify failure mode patterns. Generate eval cases semi-automatically — let the LLM draft, have a human review and approve. The human is the quality gate; the automation handles the volume.
Stage 5 — Regression gating and harness improvement proposals (Month 6+) Integrate the regression suite as a deployment gate. Add an automated step that proposes harness improvements from clustered failure modes. Engineers review proposals; approved improvements ship with full regression coverage.
Stage 5 is engineering sophistication. Stages 1-3 are just engineering discipline. Most teams stuck in production drift are stuck because they skipped stages 1-3, not because stage 5 is too complex.
Part 10: What This Means for Engineers
The self-improving system is not just an architectural upgrade. It represents a shift in how engineers relate to the systems they build.
From coding to system design. The skill that matters most is no longer writing the individual prompt or the individual validator. It is designing the feedback loop that makes all of those components improve over time. This is systems thinking, not function thinking.
From building to maintaining. A deployed AI agent is not a shipped product. It is a running process that requires continuous attention. The harness handles the structural reliability. The feedback loop handles the adaptive reliability. Neither runs without engineering investment.
From prompts to evaluation. The craft of prompt engineering — while real — is now downstream of evaluation. You cannot know if your prompt is better without an eval suite to measure against. Evaluation is the primitive. Everything else serves it.
Closing: The Systems That Learn
The future of production AI is not smarter models. Models are already remarkably capable. The limiting factor is systems that know how to stay correct as the world changes around them.
A harness makes your agent reliable at launch.
A feedback loop keeps it reliable after launch — by transforming every failure into a test case, every cluster of failures into a harness improvement, and every deployment into a regression-gated quality gate.
The engineers who understand this are not just building agents. They are building systems that learn.
Key Takeaways
- Drift is inevitable. AI systems degrade not because models change, but because the world does. Distributional shift, edge case accumulation, and regression from improvement are the three distinct failure modes.
- The feedback loop architecture: Production Traces → Failure Mining → Clustering → Eval Generation → Regression Suite → Harness Improvements → Deployment → Production
- Failures become assets when they are logged structurally and converted into eval cases.
- The regression gate enforces that the system cannot be deployed if it has regressed on previously solved problems.
- Defining good evals, avoiding eval overfitting, controlling cost, and ensuring safety are the four genuinely hard problems. Name them honestly.
- Start at Stage 1. Manual evals and structured failure logging deliver most of the value. The fully automated system comes later, built on that foundation.
Footnotes
-
MIT / Fortune, “MIT report: 95% of generative AI pilots at companies are failing,” August 2025. https://fortune.com/2025/08/18/mit-report-95-percent-generative-ai-pilots-at-companies-failing-cfo/ ↩
-
Total Shift Left, “The Future of Software Testing in AI-Driven Development,” 2026. https://totalshiftleft.ai/blog/future-software-testing-ai-driven-development ↩
-
Yohei Nakajima, “Better Ways to Build Self-Improving AI Agents.” https://yoheinakajima.com/better-ways-to-build-self-improving-ai-agents/ ↩
Discussion
Have thoughts or questions? Join the discussion on GitHub. View all discussions