AI and Data Quality: RAG Systems, Context Engineering, and the Governance Layer
How RAG systems and context engineering can poison your AI, plus the governance layer and action plan to fix data quality across your entire pipeline.
In Part 1, we covered how bad training data and vague prompts can poison your AI from the start. We saw how a $62 million system can fail because of fake training data, and how a chatbot can agree to sell a $60,000 vehicle for a dollar because of poor prompt engineering.
But here’s where it gets worse: even if you get training and prompting right, your AI can still fail catastrophically in production. The next two stages are where most teams discover their data quality problems, usually after they’ve already shipped.
Let’s dive into RAG systems and context engineering, then build the governance layer that prevents these failures from happening in the first place.
Stage 3: RAG - When Your Knowledge Base Betrays You
The problem: Retrieval-Augmented Generation (RAG) was supposed to solve AI’s hallucination problem by grounding responses in real documents. Instead, it created a whole new category of failures: garbage retrieval leading to confident nonsense.
RAG systems can still hallucinate at a 90% error rate in some domains, like when United Healthcare allegedly used a faulty AI model to deny elderly patients’ healthcare coverage. When patients appealed, nine out of ten denials were reversed. That’s not a model problem. That’s a data retrieval and quality problem.
What goes wrong:
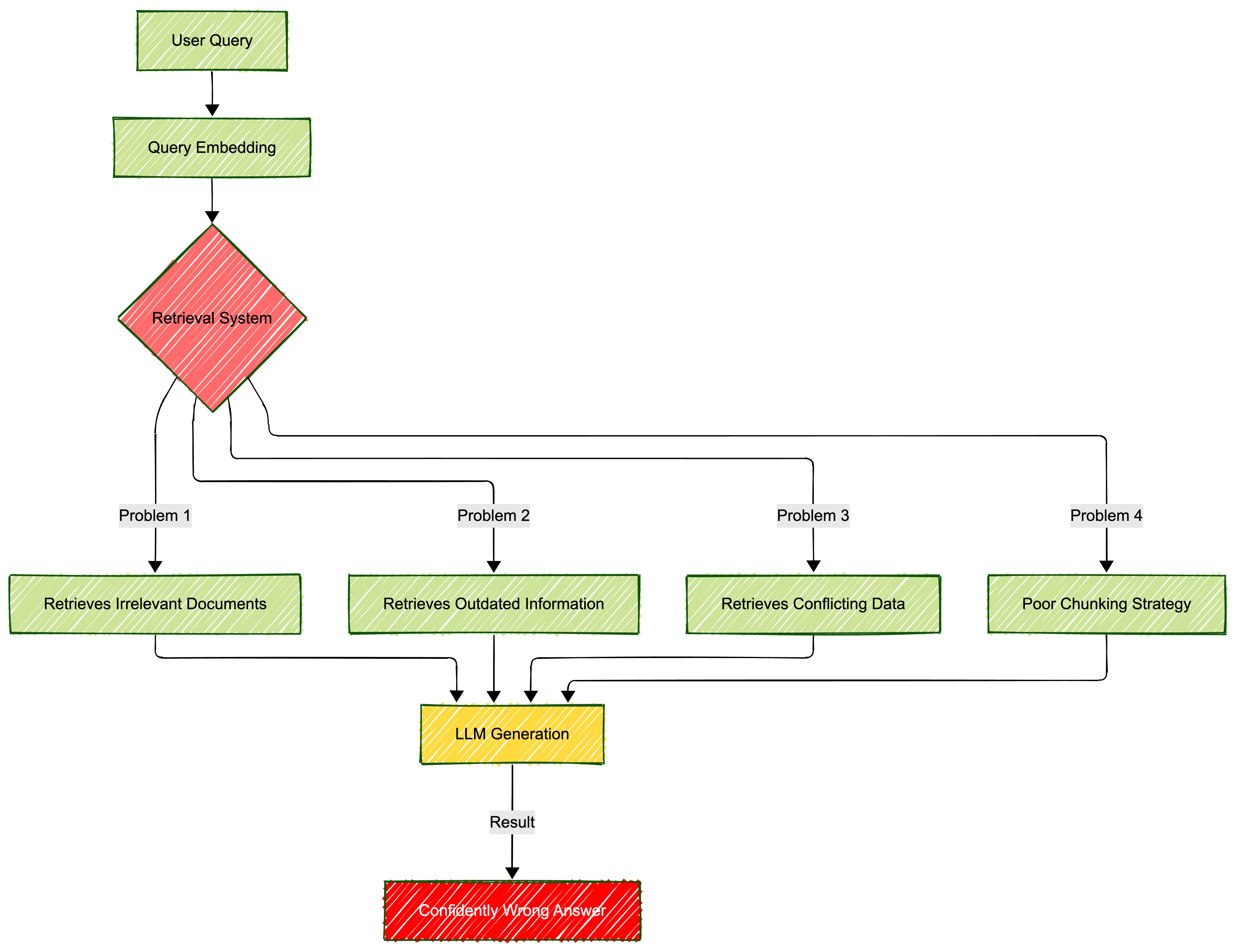
The seven deadly sins of RAG:
- Stale data: Your knowledge base hasn’t been updated since 2023, but your AI answers like it’s current
- Poor chunking: Documents split in ways that destroy context and meaning
- Irrelevant retrieval: The search brings back topically related but factually wrong documents
- Missing content: Critical information exists but isn’t retrieved because of poor indexing
- Conflicting sources: Multiple documents say different things, and the AI picks the wrong one
- Lack of source validation: No way to verify which document a claim came from
- Context overload: Too much retrieved information buries the signal in noise
Real-world example: Google’s diabetic retinopathy detection tool worked brilliantly in controlled experiments with pristine lab images. Deploy it in real clinics? It rejected more than 20% of images due to poor scan quality. The AI was trained on perfect data and couldn’t handle messy reality.
Your RAG defense architecture:
from datetime import datetime, timedelta
import numpy as np
from typing import List, Dict
class RAGQualityManager:
"""
Manage data quality for RAG systems
"""
def __init__(self, max_age_days=90, min_relevance_score=0.7):
self.max_age_days = max_age_days
self.min_relevance_score = min_relevance_score
self.quality_metrics = {
'retrieved_docs': 0,
'filtered_docs': 0,
'outdated_docs': 0,
'low_relevance_docs': 0
}
def validate_retrieved_documents(self, documents: List[Dict]) -> List[Dict]:
"""
Filter and validate retrieved documents before generation
"""
validated_docs = []
current_date = datetime.now()
for doc in documents:
self.quality_metrics['retrieved_docs'] += 1
# Check document age
doc_date = datetime.fromisoformat(doc.get('last_updated', '2020-01-01'))
age_days = (current_date - doc_date).days
if age_days > self.max_age_days:
self.quality_metrics['outdated_docs'] += 1
doc['quality_warning'] = f"Document is {age_days} days old"
# Check relevance score
relevance_score = doc.get('relevance_score', 0)
if relevance_score < self.min_relevance_score:
self.quality_metrics['low_relevance_docs'] += 1
self.quality_metrics['filtered_docs'] += 1
continue
# Check for required metadata
if not all(key in doc for key in ['source', 'content', 'last_updated']):
self.quality_metrics['filtered_docs'] += 1
continue
validated_docs.append(doc)
return validated_docs
def detect_conflicts(self, documents: List[Dict]) -> Dict:
"""
Detect conflicting information across retrieved documents
"""
conflicts = {
'has_conflicts': False,
'conflict_details': []
}
# Simple conflict detection (in production, use more sophisticated methods)
sources = [doc.get('source') for doc in documents]
if len(sources) != len(set(sources)):
conflicts['has_conflicts'] = True
conflicts['conflict_details'].append("Multiple documents from same source retrieved")
return conflicts
def get_quality_report(self) -> Dict:
"""
Generate quality metrics report
"""
total = self.quality_metrics['retrieved_docs']
if total == 0:
return self.quality_metrics
return {
**self.quality_metrics,
'quality_rate': (total - self.quality_metrics['filtered_docs']) / total,
'freshness_rate': (total - self.quality_metrics['outdated_docs']) / total
}
# Usage example
rag_manager = RAGQualityManager(max_age_days=90, min_relevance_score=0.75)
# Simulated retrieved documents
retrieved_docs = [
{
'content': 'Product pricing information...',
'source': 'pricing_guide_2025.pdf',
'last_updated': '2025-12-01',
'relevance_score': 0.92
},
{
'content': 'Old product information...',
'source': 'legacy_docs.pdf',
'last_updated': '2023-01-15',
'relevance_score': 0.85
}
]
validated_docs = rag_manager.validate_retrieved_documents(retrieved_docs)
conflicts = rag_manager.detect_conflicts(validated_docs)
quality_report = rag_manager.get_quality_report()
print(f"Quality Report: {quality_report}")
print(f"Conflicts Detected: {conflicts}")
RAG best practices checklist:
✅ Freshness monitoring: Set expiration dates on documents and auto-flag stale content
✅ Reranking: Don’t trust initial retrieval scores; use a second model to rerank by actual relevance
✅ Source attribution: Always track which document each claim came from
✅ Conflict detection: Implement systems to catch when retrieved documents contradict each other
✅ Chunk validation: Test your chunking strategy to ensure context isn’t lost
✅ Retrieval metrics: Track precision, recall, and relevance scores continuously
✅ Hallucination detection: Use LLM-based or token similarity methods to catch fabricated content
When AI fails in production, the model is rarely broken - the knowledge base that fed it was poisoned from day one.
Stage 4: Context Engineering - When More Context Creates More Problems
The problem: Context is supposed to help AI understand what you need. But in 2026, AI systems are drowning in context. Token limits have grown massive, but your AI’s ability to extract meaningful signals from noise hasn’t kept pace.
Think of it like giving someone a 500-page manual when they just asked how to turn on the lights. Sure, the answer is in there somewhere, but good luck finding it.
What goes wrong:
- Context overload: Too much information buries critical details
- Token budget exhaustion: Hitting model limits means dropping important context
- Context poisoning: Malicious or incorrect information in context misleads the model
- Context drift: Long conversations lose coherence as earlier context fades
- Poor context structure: Unorganized information makes it hard for AI to navigate
Real-world consequences: When building agentic AI systems (think autonomous coding agents or multi-step reasoning systems), context management becomes life or death. An agent that loses track of its goals or forgets critical constraints can:
- Delete important files thinking they’re temporary
- Authorize transactions it shouldn’t
- Generate code with security vulnerabilities
- Make decisions based on outdated context
Context management architecture:
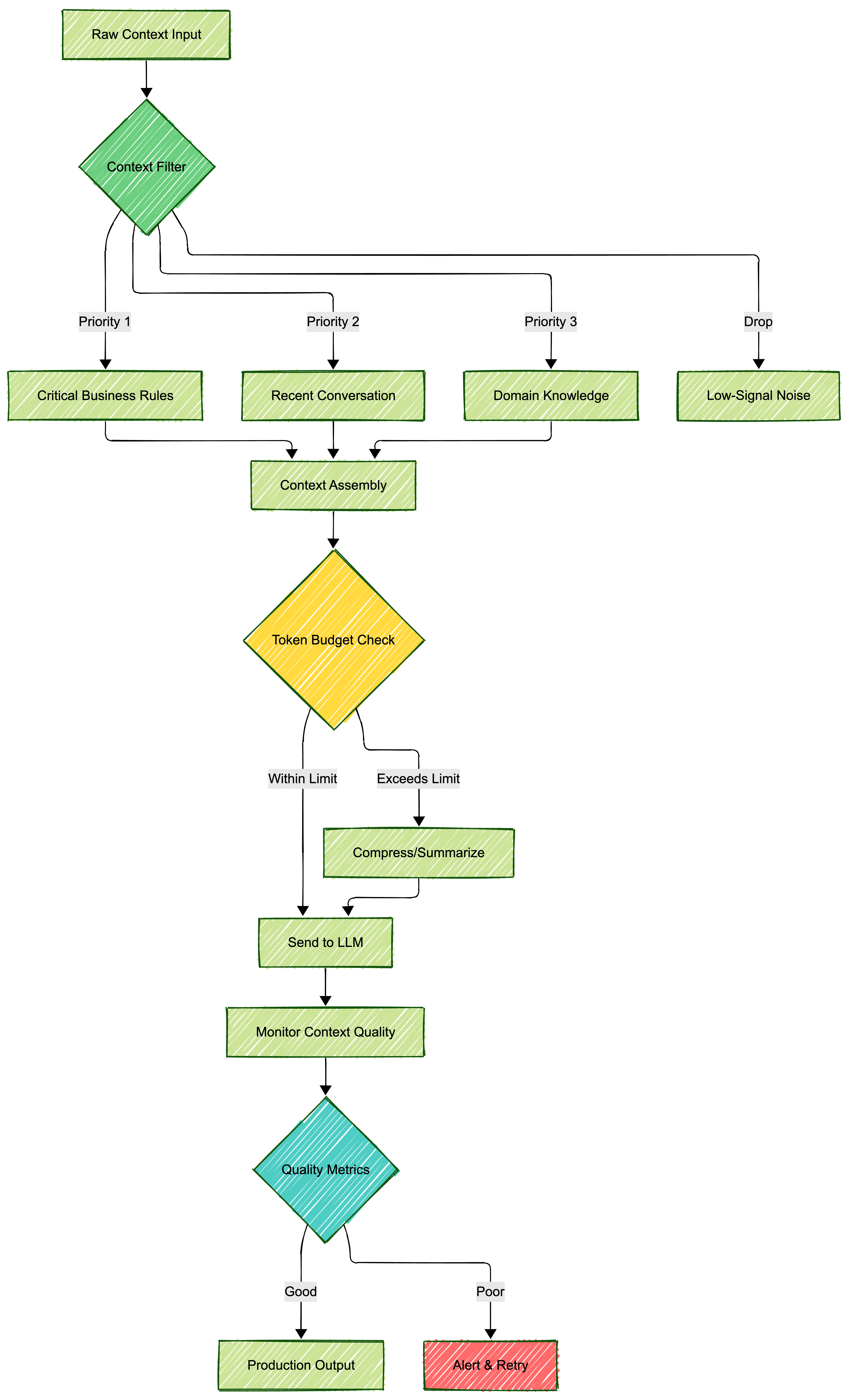
Context engineering best practices:
from typing import List, Dict, Tuple
import tiktoken
class ContextEngineer:
"""
Manage context quality and token budgets for LLM calls
"""
def __init__(self, model_name="gpt-4", max_tokens=8000):
self.encoder = tiktoken.encoding_for_model(model_name)
self.max_tokens = max_tokens
self.context_priorities = {
'critical_rules': 1,
'recent_conversation': 2,
'domain_knowledge': 3,
'background_info': 4
}
def count_tokens(self, text: str) -> int:
"""Count tokens in text"""
return len(self.encoder.encode(text))
def prioritize_context(self, context_items: List[Dict]) -> List[Dict]:
"""
Sort context items by priority and relevance
"""
return sorted(
context_items,
key=lambda x: (
self.context_priorities.get(x['type'], 99),
-x.get('relevance_score', 0)
)
)
def build_optimized_context(self, context_items: List[Dict]) -> Tuple[str, Dict]:
"""
Build context string that fits within token budget
"""
sorted_items = self.prioritize_context(context_items)
context_parts = []
total_tokens = 0
items_included = 0
items_dropped = 0
for item in sorted_items:
item_text = f"\n## {item['type'].upper()}\n{item['content']}\n"
item_tokens = self.count_tokens(item_text)
if total_tokens + item_tokens <= self.max_tokens:
context_parts.append(item_text)
total_tokens += item_tokens
items_included += 1
else:
items_dropped += 1
print(f"Dropping context item '{item['type']}' - exceeds token budget")
metrics = {
'total_tokens': total_tokens,
'items_included': items_included,
'items_dropped': items_dropped,
'token_utilization': total_tokens / self.max_tokens
}
return "\n".join(context_parts), metrics
def validate_context_quality(self, context: str) -> Dict:
"""
Check context for common quality issues
"""
issues = []
# Check for redundancy
lines = context.split('\n')
unique_lines = set(lines)
if len(lines) - len(unique_lines) > 5:
issues.append("High redundancy detected in context")
# Check for conflicting information
if 'however' in context.lower() and 'but' in context.lower():
issues.append("Potential conflicting statements in context")
# Check token density
words = context.split()
tokens = self.count_tokens(context)
words_per_token = len(words) / tokens if tokens > 0 else 0
if words_per_token < 0.5:
issues.append("Low information density - context may be inefficient")
return {
'has_issues': len(issues) > 0,
'issues': issues,
'quality_score': max(0, 1 - (len(issues) * 0.2))
}
# Usage example
engineer = ContextEngineer(model_name="gpt-4", max_tokens=4000)
context_items = [
{
'type': 'critical_rules',
'content': 'Never delete files without user confirmation. Always validate inputs.',
'relevance_score': 1.0
},
{
'type': 'recent_conversation',
'content': 'User asked to analyze sales data from Q4 2025',
'relevance_score': 0.95
},
{
'type': 'domain_knowledge',
'content': 'Company average deal size is $150K. Sales cycle is 90 days.',
'relevance_score': 0.8
},
{
'type': 'background_info',
'content': 'Historical context from 2023... (long text)',
'relevance_score': 0.3
}
]
optimized_context, metrics = engineer.build_optimized_context(context_items)
quality_check = engineer.validate_context_quality(optimized_context)
print(f"Context Metrics: {metrics}")
print(f"Quality Check: {quality_check}")
Essential context engineering principles:
- Prioritize ruthlessly: Not all context is created equal. Critical business rules > recent conversation > background info
- Structure semantically: Organize context in a way that makes sense to both humans and AI
- Monitor token budgets: Know exactly how much context you’re using and optimize accordingly
- Validate continuously: Check for redundancy, conflicts, and low-quality information
- Implement memory systems: For multi-turn conversations, maintain a structured memory of what matters
More context doesn’t mean better understanding; it means more ways to get confused.
The Governance Layer: Your Safety Net
Here’s what separates AI projects that succeed from the 80% that fail: governance. Not the boring compliance checkbox kind, but active, intelligent data governance that catches problems before they become disasters.
What robust AI data governance looks like:
Data Lineage and Traceability
Know exactly where your data came from, who touched it, and how it was transformed. When something goes wrong (and it will), you need to trace the problem back to its source.
from datetime import datetime
class DataLineageTracker:
"""
Track data transformations and sources
"""
def __init__(self):
self.lineage = []
def log_transformation(self, stage, source, transformation, output_quality):
"""
Log each data transformation step
"""
entry = {
'timestamp': datetime.now().isoformat(),
'stage': stage,
'source': source,
'transformation': transformation,
'quality_metrics': output_quality
}
self.lineage.append(entry)
# Alert on quality degradation
if output_quality.get('quality_score', 1.0) < 0.7:
print(f"⚠️ Quality alert at {stage}: {output_quality}")
def trace_back(self, issue_stage):
"""
Trace back from an issue to find root cause
"""
relevant_history = [
entry for entry in self.lineage
if entry['stage'] == issue_stage or entry['stage'] in ['training', 'preprocessing']
]
return relevant_history
# Usage
tracker = DataLineageTracker()
tracker.log_transformation(
stage='preprocessing',
source='raw_data.csv',
transformation='remove_duplicates',
output_quality={'quality_score': 0.95, 'rows_removed': 1200}
)
Access Controls and Audit Trails
In healthcare RAG, in financial AI, in any system handling sensitive data: who accessed what, when, and why must be logged and monitored.
Real-time Quality Monitoring
Don’t wait for users to report hallucinations. Monitor for them continuously in production.
Bias Detection and Mitigation
Your AI will learn and amplify any biases in your data. Test for bias systematically, across demographic groups, use cases, and time periods.
Security Measures
Data quality isn’t just about accuracy. It’s about security. Poisoned training data, adversarial inputs, and prompt injection attacks are real threats that require:
- Input sanitization
- Output validation
- Anomaly detection
- Access controls
- Encryption at rest and in transit
Governance isn’t about saying no; it’s about catching disasters before they ship.
Your Action Plan: What to Do Monday Morning
Stop reading about problems and start solving them. Here’s your 30-day data quality transformation:
Week 1: Audit and Assess
Day 1-2: Run automated data profiling on all training datasets
Day 3-4: Review last 100 AI outputs for hallucinations or errors
Day 5: Map your data pipeline from source to production
Week 2: Implement Quick Wins
Day 6-8: Add basic data validation checks (duplicates, nulls, outliers)
Day 9-10: Implement prompt templates with validation
Week 3: Build Monitoring
Day 11-13: Set up data quality dashboards
Day 14-15: Implement RAG quality metrics (retrieval accuracy, freshness)
Week 4: Establish Governance
Day 16-20: Create data lineage tracking
Day 21-25: Implement access controls and audit logs
Day 26-30: Document data quality SLAs and responsibilities
Free tools to get started:
- Great Expectations: Data validation framework
- Pandas Profiling: Automated EDA reports
- LangSmith: LLM observability and debugging
- Weights & Biases: ML experiment tracking
- DVC: Data version control
The Bottom Line
Let me leave you with this: IBM’s Watson for Oncology cost $62 million and gave dangerous medical advice because of bad training data (academic study). McDonald’s AI drive-thru kept adding McNuggets until it reached 260 pieces because of poor prompt engineering. United Healthcare’s AI denied 90% of elderly patients’ coverage incorrectly because of flawed RAG systems.
These aren’t small startups making rookie mistakes. These are billion-dollar companies with world-class engineering teams. And they all failed the same test: data quality.
The uncomfortable truth is that your AI is only as good as your worst data quality problem. You can have the smartest model, the fastest hardware, and the best engineers. But if your data is garbage, your AI will fail. Not might fail. Will fail.
The good news? Unlike algorithmic improvements or hardware upgrades, data quality is something you can actually control. It requires discipline, process, and continuous monitoring, but it’s entirely within your power to fix.
So before you train your next model, before you ship your next feature, before you scale your AI to production, ask yourself: Is my data good enough to bet the company on?
Because in 2026, that’s exactly what you’re doing.
Key Takeaways (The Only Thing You Need to Remember)
🎯 AI doesn’t create garbage; it recycles your mess at warp speed
🎯 92.7% of executives say data quality is the #1 barrier to AI success
🎯 Bad data poisons AI at four critical stages: training, prompting, RAG, and context engineering
🎯 Vague prompts produce vague results. Precision in, precision out
🎯 RAG systems don’t eliminate hallucinations; they move them to your knowledge base
🎯 More context doesn’t mean better understanding; it means more ways to get confused
🎯 Governance isn’t about saying no; it’s about catching disasters before they ship
🎯 The model is rarely broken. The data that fed it was poisoned from day one
Further Reading
- Informatica CDO Insights 2025 - Survey on AI data readiness challenges
- Gartner on AI-Ready Data - Why 60% of AI projects will fail without proper data
- Stanford Legal RAG Study - Comprehensive analysis of hallucinations in RAG systems
- AWS RAG Hallucination Detection - Practical implementation guide
- Prompt Engineering Guide 2025 - Best practices for production systems
What’s Next
Internal links:
- AI and Data Quality: The $12.9 Million Problem and How Training Data Poisons Your AI - Previous in the Production Operations series
- The Anatomy of a Production LLM Call - Building production-ready LLM integrations
- Prompt Engineering: The Difference Between Demos and Production - How to design prompts that survive production
Disclaimer: The views and opinions expressed on this site are my own and do not necessarily reflect those of my employer. Content is provided for informational purposes based on my experience building AI systems. Technical implementations and approaches may vary based on specific use cases, organizational requirements, and versions of tools, packages, and software dependencies.
External Links: This blog may contain links to external websites, resources, and citations. I am not responsible for the content, privacy practices, or security of external sites. External links open in a new tab for your convenience. Please review the privacy policies and terms of service of any external sites you visit.
About This Series: This post is part of the Production Operations series on yellamaraju.com/blog, focusing on running AI systems reliably in production. This series covers observability, testing, cost optimization, debugging, and data quality - the essential practices that separate successful AI deployments from expensive failures.
Last updated: January 2026
Discussion
Have thoughts or questions? Join the discussion on GitHub. View all discussions